kaggle :ScatterLine (Q42)
kaggle dictation (08)
plotly.graph_objects as go_ Scatter + line plot
산점도
- bivariate”이변수” 값을 시각화 하는 기본적인 그래프.
- correlation: Positive, Negative, non
- 두 개의 변수 각각의 분포과 변수간의 관계를 확인 할 수 있다.
ref.
0. data set
https://www.kaggle.com/miguelfzzz/the-typical-kaggle-data-scientist-in-2021
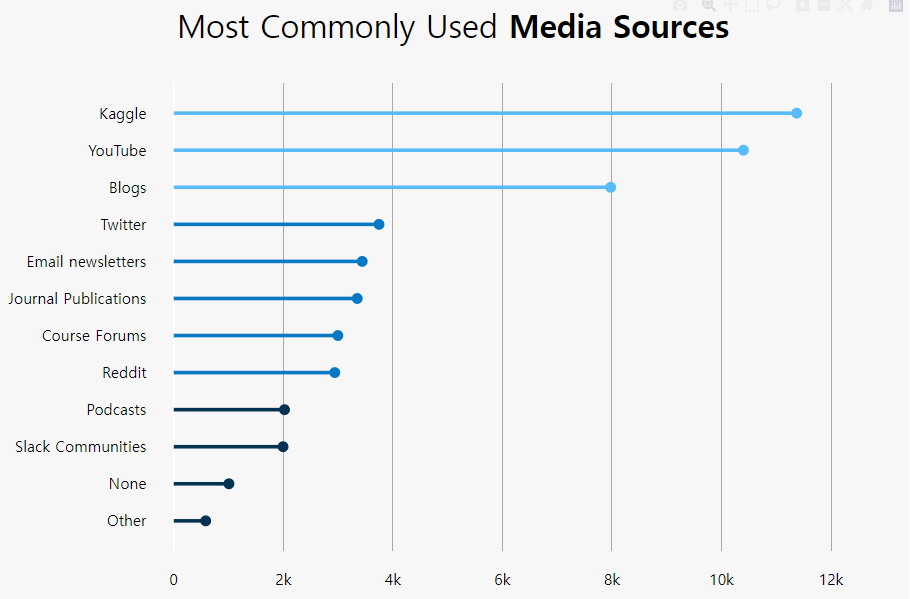
Subject : 가장 많이 이용하는 Media source
1. data 읽어오기
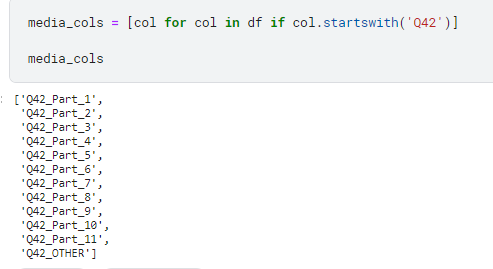
Q42로 시작하는 col을 읽어오기.
python의 for문을 이용.
1 | media_cols = [col for col in df if col.startswith('Q42')] |
2. data Frame 만들어 주기
1 | media = df[media_cols] |
3.표 설정.
1 | media = ( |
4. 색 지정
1 |
|
5. percent로 계산한 column 추가
i. add percent column
1 | media['percent'] = ((media['Count'] / len(df))*100).round(2).astype(str) + '%' |
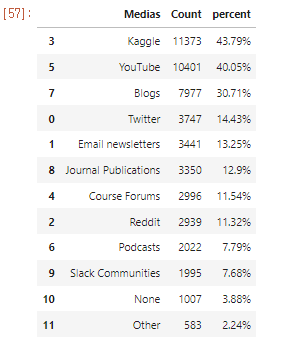
ii. Count값 (column값으로 ) 정렬
1 | media = (media |
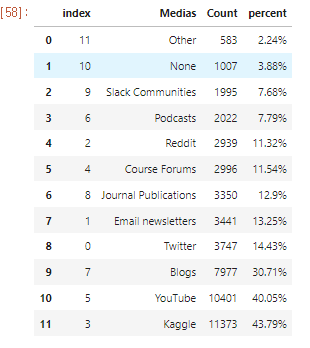
1. Default는 내림차순
2. iloc으로 0번부터 15까지 List로 긁어오기
3. reset index()
6.plotly.graph_objects.Scatter()
Scatter G 그리기
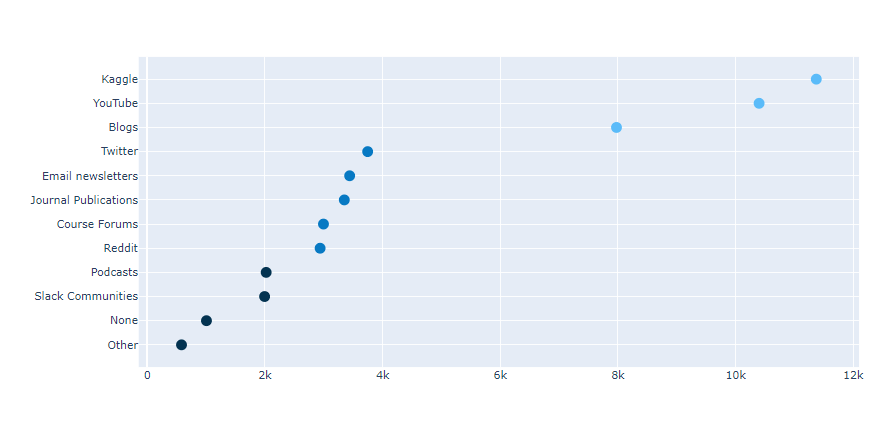
i. 산점도 점 찍기
1 |
|
ii. 산점도에 for문을 이용하여 line 연결하기
1 | for i in range(0, len(media)): |
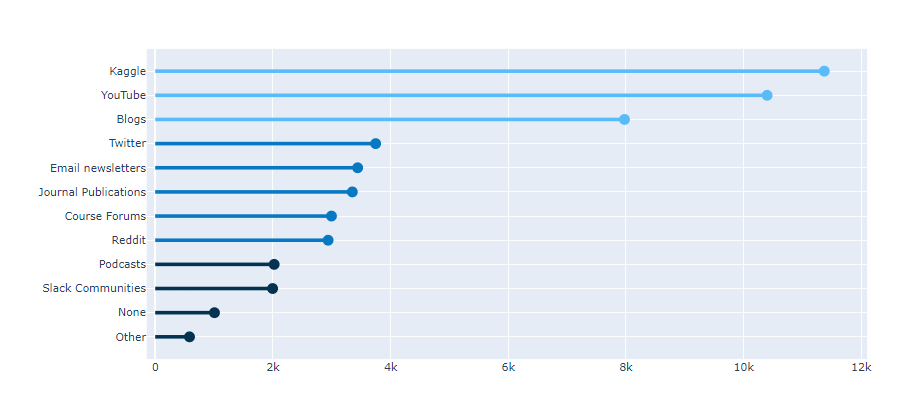
- for i in range(0~platform의 길이만큼)
- fig. add_shape()
- type = ‘line’
- line모양의 grape shape add
- line모양의 grape shape add
- x0 = 0, y0 = i,
- 초기값 (0, i)에서 시작
- (0, 0) = other Line Start
- x1 = platform[“Count”][i],
- x축 Index : count의 값만큼 x축방향으로 Line이 그어진다.
- y1 = i,
- y축 Index, 마지막 값
- y축 Index, 마지막 값
- line=dict(color=colors[i], width = 4)
- line의 세부 설정, 색과 두께
- type = ‘line’
7. update_traces(hovertemplate)
1 | fig.update_traces(hovertemplate='<b>Media Source</b>: %{y}<br><extra></extra>'+ |
8. Design
i. 축 grid
1 | fig.update_xaxes(showgrid=True, gridwidth=1, gridcolor='#9f9f9f', ticklabelmode='period') |
x 축의 grid만 보여줌. tick labe lmode : period
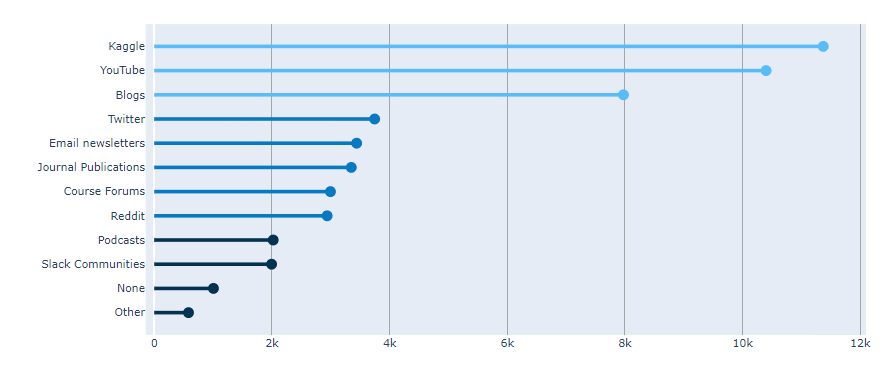
ii. update_layout()
1 |
|
9. Annotation
1 | fig.add_annotation(dict(font=dict(size=14), |
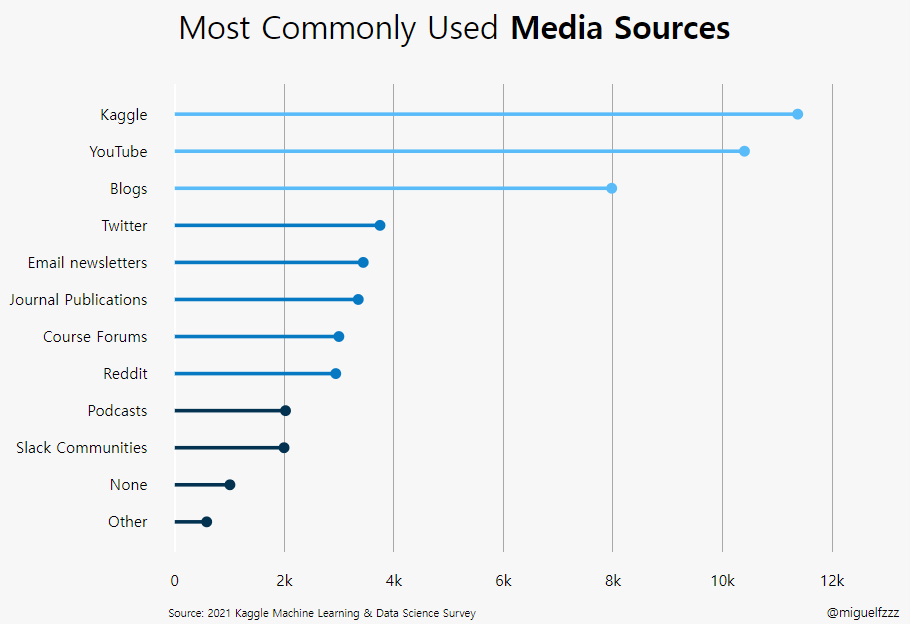
kaggle :ScatterLine (Q42)
https://yoonhwa-p.github.io/2021/11/09/kgg/Kgg_plotly_ScatterL(2)/
You need to set
install_url to use ShareThis. Please set it in _config.yml.