library(ggplot2) # 시각화 코드 # install.packages("dplyr") # install.packages("tidyr") library(dplyr) # 데이터 가공 library(reshape) # 데이터 가공 <-- tidyr library(readr) # 파일 입출력
# ---- 훈련 검증용 데이터 분류 ---- set.seed(1234) idx = sample(1:nrow(pos_final_df), nrow(pos_final_df) * 0.7, replace = FALSE) train = pos_final_df[idx, ] test = pos_final_df[-idx, ]
Logistic Regression Model Develop
1 2 3 4 5 6 7 8 9 10 11
# --- 로지스틱 회귀 모형 개발 ---
start_time = Sys.time()
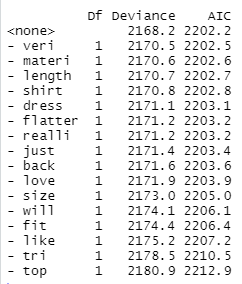
glm_model = step(glm(pos_binary ~ ., data = train[-1], family = binomial(link = "logit")), direction = "backward") # 후진소거법
End_time = Sys.time() difftime(End_time, start_time, units = "secs")
Step: AIC=2202.56
Logistic regression 안의 평가 기준
낮을 수록 좋다.
Step: AIC=2202.2 pos_binary ~ love + veri + just + size + dress + fit + will + back + like + tri + flatter + top + length + realli + shirt + materi
모형 성능 측정
1 2 3 4 5 6
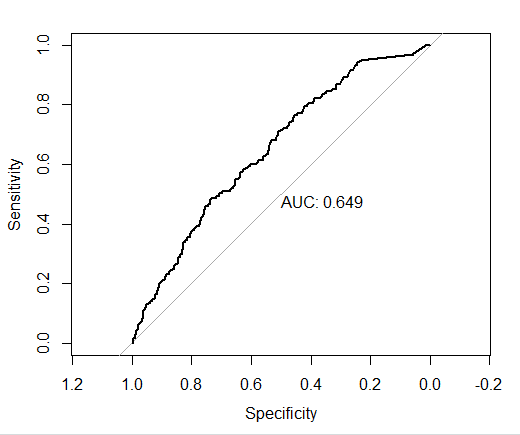
# ---- 모형 성능 측정 ---- # install.packages("pROC") library(pROC) preds = predict(glm_model, newdata = test, type = "response") roc_glm = roc(test$pos_binary, preds) plot.roc(roc_glm, print.auc=TRUE)
정리
1. 정형 데이터 가져 오기
2. 정형 데이터 가공
- 좋아요 수를 활용하여 긍정/부정 data 나눔
3. 정형 데이터 분리 : 텍스트 데이터 따로 분리
4. 텍스트 데이터 처리 (전처리, 토큰화, 코퍼스, DTM)
5. 텍스트 데이터 + 기존 data 합침
6. ML 모형 진행 (다른 모형을 진행 해도 된다. )
하지만, 혹시 지금까지 배운 내용이 너무 어렵다면 python으로만 하는 것도 나쁘지 않다.