이어지는 포스팅 :
Kgg_TPS 02
Description of competition
data overview
Kaggle에서 매달 1일에 data scientists의 Featured competitions을 위해 beginner- friendly로 제공하는 대회
- 대회의 목적 : a fun, and approachable 를 위해 anyone에게 tabular dataset 제공.
- dataset : CTGAN에서 만들어진 숲 토양 타입 예측 대회 data
The study area includes four wilderness areas located in
the Roosevelt National Forest of northern Colorado.
Each observation is a 30m x 30m patch.
You are asked to predict an integer classification for the forest cover type(FCT).
The seven types are:
2 - Lodgepole Pine
3 - Ponderosa Pine
4 - Cottonwood/Willow
5 - Aspen
6 - Douglas-fir
7 - Krummholz
The training set (15120 observations) contains both features and the Cover_Type.
The test set contains only the features.
You must predict the Cover_Type for every row in the test set (565892 observations).
Data Fields
Elevation - 미터 단위 고도
Aspect - 방위각의 종횡비 (위치)
Slope - 경사 기울기
Horizontal_Distance_To_Hydrology - 해수면까지의 수평거리
Vertical_Distance_To_Hydrology - 해수면까지의 수직거리
Horizontal_Distance_To_Roadways - 도로와의 수평 거리
Hillshade_9am (0 to 255 index) - 여름, 오전 9시 Hillshade
Hillshade_Noon (0 to 255 index) - 여름, 정오 Hillshade
Hillshade_3pm (0 to 255 index) - 여름, 오후 3시 Hillshade
Horizontal_Distance_To_Fire_Points - 산불 발화점까지 수평거리
Wilderness_Area
: 야생지역- 4 개의 columns (토양 유형 지정)
+ 0 = 없음
+ 1 = 있음
Soil_Type
: 토양 유형 지정- 40 개의 columns
+ 0 = 없음
+ 1 = 있음
Cover_Type
FCT 지정br> - 7 개 columns
+ 0 = 없음
+ 1 = 있음
The wilderness areas are:
1 - Rawah Wilderness Area
2 - Neota Wilderness Area
3 - Comanche Peak Wilderness Area
4 - Cache la Poudre Wilderness Area
The soil types are:
1 Cathedral family - Rock outcrop complex, extremely stony.
2 Vanet - Ratake families complex, very stony.
3 Haploborolis - Rock outcrop complex, rubbly.
4 Ratake family - Rock outcrop complex, rubbly.
5 Vanet family - Rock outcrop complex complex, rubbly.
6 Vanet - Wetmore families - Rock outcrop complex, stony.
7 Gothic family. Na
8 Supervisor - Limber families complex.
9 Troutville family, very stony.
10 Bullwark - Catamount families - Rock outcrop complex, rubbly.
11 Bullwark - Catamount families - Rock land complex, rubbly.
12 Legault family - Rock land complex, stony.
13 Catamount family - Rock land - Bullwark family complex, rubbly.
14 Pachic Argiborolis - Aquolis complex.
15 unspecified in the USFS Soil and ELU Survey. (Na)
16 Cryaquolis - Cryoborolis complex.
17 Gateview family - Cryaquolis complex.
18 Rogert family, very stony.
19 Typic Cryaquolis - Borohemists complex.
20 Typic Cryaquepts - Typic Cryaquolls complex.
21 Typic Cryaquolls - Leighcan family, till substratum complex.
22 Leighcan family, till substratum, extremely bouldery.
23 Leighcan family, till substratum - Typic Cryaquolls complex.
24 Leighcan family, extremely stony.
25 Leighcan family, warm, extremely stony.
26 Granile - Catamount families complex, very stony.
27 Leighcan family, warm - Rock outcrop complex, extremely stony.
28 Leighcan family - Rock outcrop complex, extremely stony.
29 Como - Legault families complex, extremely stony.
30 Como family - Rock land - Legault family complex, extremely stony.
31 Leighcan - Catamount families complex, extremely stony.
32 Catamount family - Rock outcrop - Leighcan family complex, extremely stony.
33 Leighcan - Catamount families - Rock outcrop complex, extremely stony.
34 Cryorthents - Rock land complex, extremely stony.
35 Cryumbrepts - Rock outcrop - Cryaquepts complex.
36 Bross family - Rock land - Cryumbrepts complex, extremely stony.
37 Rock outcrop - Cryumbrepts - Cryorthents complex, extremely stony.
38 Leighcan - Moran families - Cryaquolls complex, extremely stony.
39 Moran family - Cryorthents - Leighcan family complex, extremely stony.
40 Moran family - Cryorthents - Rock land complex, extremely stony.
- 경사(Slope) : 어떤 지점의 지반이 수평을 기준으로 몇도 기울어져 있는가
- θ(theta) 로 표현
- 각이 클 수록 지반의 경사가 급하고 각이 0이면 평편한 지반
- 향(Aspect): 지반의 경사면이 어디를 향하는가
- 북: 0도, 동: 90도, 남: 180도, 서: 270도.
- 완전히 평편할 경우 GIS 시스템마다 다른 값, Null 가능, (-1과 같은 값이 적당)
Evaluation
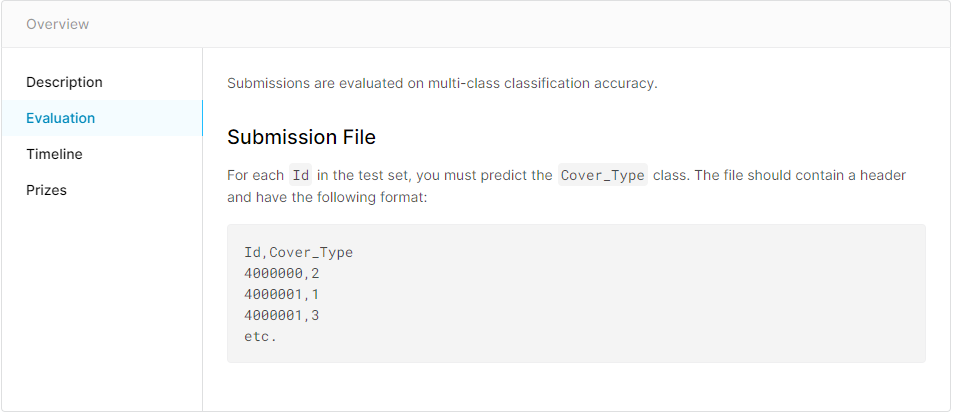
각각의 ID 를 cover type 과 Matching하여 file format 형태를 만들어 제출 하면 됩니다.