with mlflow.start_run(run_name="MLflow on Colab"): mlflow.log_metric("m1", 2.0) mlflow.log_param("p1", "mlflow-colab")
# run tracking UI in the background get_ipython().system_raw("mlflow ui --port 5000 &") # run tracking UI in the background
# create remote tunnel using ngrok.com to allow local port access # borrowed from https://colab.research.google.com/github/alfozan/MLflow-GBRT-demo/blob/master/MLflow-GBRT-demo.ipynb#scrollTo=4h3bKHMYUIG6
from pyngrok import ngrok
# Terminate open tunnels if exist ngrok.kill()
# Setting the authtoken (optional) # Get your authtoken from https://dashboard.ngrok.com/auth NGROK_AUTH_TOKEN = "" ngrok.set_auth_token(NGROK_AUTH_TOKEN)
# Open an HTTPs tunnel on port 5000 for http://localhost:5000 ngrok_tunnel = ngrok.connect(addr="5000", proto="http", bind_tls=True) print("MLflow Tracking UI:", ngrok_tunnel.public_url)
|████████████████████████████████| 745 kB 5.4 MB/s
Building wheel for pyngrok (setup.py) ... done
---------------------------------------
Exception Traceback (most recent call last) in ()
4 import mlflow
5
----> 6 with mlflow.start_run(run_name="MLflow on Colab"):
7 mlflow.log_metric("m1", 2.0)
8 mlflow.log_param("p1", "mlflow-colab")
/usr/local/lib/python3.7/dist-packages/mlflow/tracking/fluent.py in start_run(run_id, experiment_id, run_name, nested, tags)
229 + “current run with mlflow.end_run(). To start a nested “
230 + “run, call start_run with nested=True”
–> 231 ).format(_active_run_stack[0].info.run_id)
232 )
233 client = MlflowClient()
Exception: Run with UUID 3cbca838cdd44eac8620700ac1929a64 is already active.
To start a new run, first end the current run with mlflow.end_run().
To start a nested run, call start_run with nested=True
# This Python 3 environment comes with many helpful analytics libraries installed # It is defined by the kaggle/python Docker image: https://github.com/kaggle/docker-python # For example, here's several helpful packages to load
import numpy as np # linear algebra import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
# Input data files are available in the read-only "../input/" directory # For example, running this (by clicking run or pressing Shift+Enter) will list all files under the input directory
import os for dirname, _, filenames in os.walk('/kaggle/input'): for filename in filenames: print(os.path.join(dirname, filename))
# You can write up to 20GB to the current directory (/kaggle/working/) that gets preserved as output when you create a version using "Save & Run All" # You can also write temporary files to /kaggle/temp/, but they won't be saved outside of the current session
데이터 다운로드 및 불러오기
1 2 3 4 5 6 7
import pandas as pd
train = pd.read_csv("/kaggle/input/house-prices-advanced-regression-techniques/train.csv") test = pd.read_csv("/kaggle/input/house-prices-advanced-regression-techniques/test.csv")
train.shape, test.shape #변수를 줄여야 겠다. 어떤 변수를 줄여야 할까 ?
import seaborn as sns import matplotlib.pyplot as plt from scipy.stats import norm
(mu, sigma) = norm.fit(train['SalePrice']) print("The value of mu before log transformation is:", mu) print("The value of sigma before log transformation is:", sigma)
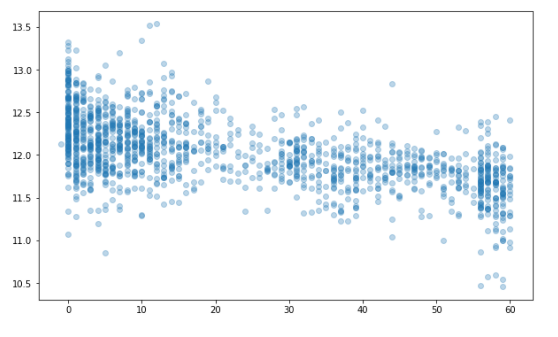
train["SalePrice"] = np.log1p(train["SalePrice"]) # 로그 변환 후 종속 변수 시각화
(mu, sigma) = norm.fit(train['SalePrice']) print("The value of mu before log transformation is:", mu) print("The value of sigma before log transformation is:", sigma)
#object column, 갯수 확인 import numpy as np cat_all_vars = train.select_dtypes(exclude=[np.number]) #숫자인 것을 제외한 type column 이름 추출 print("The whole number of all_vars(문자형data)", len(list(cat_all_vars)))
#column 이름 뽑아내기 final_cat_vars = [] for v in cat_all_vars: if v notin ['PoolQC', 'MiscFeature', 'Alley', 'Fence', 'FireplaceQu', 'LotFrontage']: final_cat_vars.append(v)
print("The whole number of final_cat_vars", len(final_cat_vars))
#최빈값을 찾아 넣어주기 for i in final_cat_vars: all_df[i] = all_df[i].fillna(all_df[i].mode()[0])
check_na(all_df, 20) print("숫자형 data set의 결측치만 남은 것을 알 수 있다. ")
1 2 3 4 5 6 7 8 9 10 11 12
import numpy as np num_all_vars = list(train.select_dtypes(include=[np.number])) print("The whole number of all_vars", len(num_all_vars))
num_all_vars.remove('LotFrontage')
print("The whole number of final_cat_vars", len(num_all_vars)) for i in num_all_vars: all_df[i].fillna(value=all_df[i].median(), inplace=True)
print("결측치가 존재 하지 않은 것을 알 수 있다. ") check_na(all_df, 20)
1
all_df.info()
왜도(Skewnewss) 처리하기 : 정규 분포를 이룰 수 있게 (설문조사 논문 통계의 경우 -1< 외도 <1)
boxcose를 사용 할 예정
왜도가 양수일때, 음수일때 (좌, 우로 치우친 정도)
첨도가 양수일때, 음수일때 (뽀족한 정도)
RMSE를 최적(낮게)으로 만들기 위해 조정.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
from scipy.stats import skew
#외도 판정을 받을 만한 data set을 확인 deffind_skew(x): return skew(x) #앞에서 뽑은 numeric columns : num_all_vars #사용자 정의함수를 쓰기 위해 apply(find_skew)를 사용, 오름차순정렬
#0~1사이에 있는 것이 기준. 기준 밖으로 나간 경우 조정이 필요(정규분포를 만들어 주기 위해) # 1. 박스코스 변환 : ML -> RMSE (2.5) # 2. 로그변환 : ML -> RMSE (2.1) # => RMSE는 적은 것이 좋기 때문에, 로그 변환으로 사용 하는 것이 좋다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14
skewnewss_index = list(skewness_features.index) skewnewss_index.remove('LotArea') #외도 정도가 너무 높은 LotArea를 날려주는 것. all_numeric_df = all_df.loc[:, skewnewss_index]
fig, ax = plt.subplots(figsize=(10, 6)) ax.set_xlim(0, all_numeric_df.max().sort_values(ascending=False)[0]) ax = sns.boxplot(data=all_numeric_df[skewnewss_index] , orient="h", palette="Set1") ax.xaxis.grid(False) ax.set(ylabel="Feature names") ax.set(xlabel="Numeric values") ax.set(title="Numeric Distribution of Features Before Box-Cox Transformation") sns.despine(trim=True, left=True)
1 2 3 4 5 6 7 8 9 10 11 12
from scipy.special import boxcox1p from scipy.stats import boxcox_normmax
따라서 data 정의서 먼저 봐야 한다. : data description.txt를 먼저 봐야 한다. !!! (실무에서는 없는 경우가 많다.)
시각화 : 각각의 data 무한작업, 도메인 공부
1 2 3 4 5 6 7 8 9 10 11
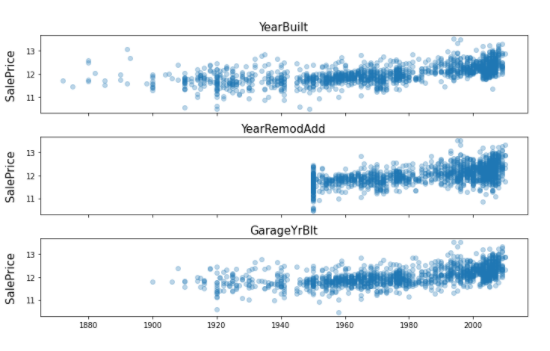
# 연도와 관련된. num_all_vars = list(train.select_dtypes(include=[np.number])) year_feature = [] for var in num_all_vars: if'Yr'in var: year_feature.append(var) elif'Year'in var: year_feature.append(var) else: print(var, "is not related with Year") print(year_feature)
1 2 3 4 5 6 7 8
fig, ax = plt.subplots(3, 1, figsize=(10, 6), sharex=True, sharey=True) for i, var inenumerate(year_feature): if var != 'YrSold': ax[i].scatter(train[var], y, alpha=0.3) ax[i].set_title('{}'.format(var), size=15) ax[i].set_ylabel('SalePrice', size=15, labelpad=12.5) plt.tight_layout() plt.show()
from sklearn.metrics import mean_squared_error from sklearn.model_selection import KFold, cross_val_score from sklearn.linear_model import LinearRegression
defcv_rmse(model, n_folds=5): cv = KFold(n_splits=n_folds, random_state=42, shuffle=True) rmse_list = np.sqrt(-cross_val_score(model, X, y, scoring='neg_mean_squared_error', cv=cv)) print('CV RMSE value list:', np.round(rmse_list, 4)) print('CV RMSE mean value:', np.round(np.mean(rmse_list), 4)) return (rmse_list)
from sklearn.ensemble import RandomForestRegressor, GradientBoostingRegressor from sklearn.tree import DecisionTreeRegressor from sklearn.linear_model import LinearRegression
# LinearRegresison lr_model = LinearRegression()
# Tree Decision tree_model = DecisionTreeRegressor()
# Random Forest Regressor rf_model = RandomForestRegressor()
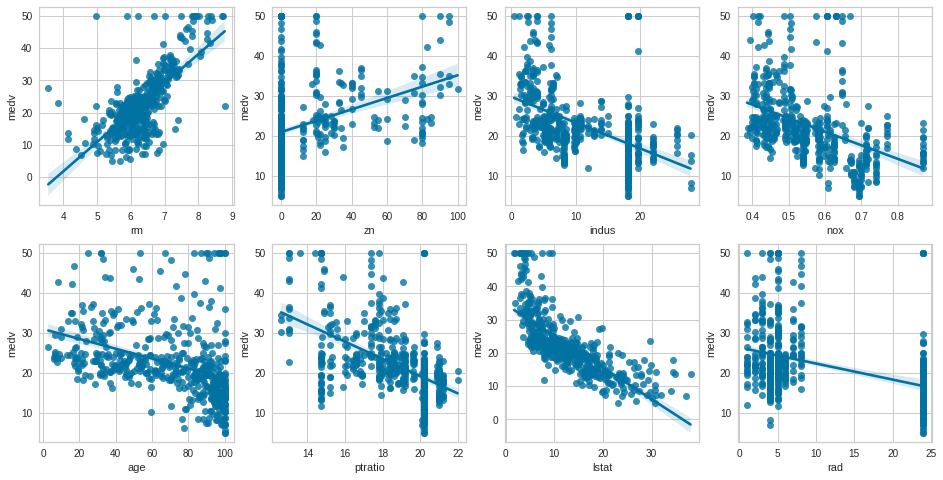
for i, feature inenumerate(lm_features): row = int(i/4) col = i%4 print("row is {}, col is {}".format(row, col)) sns.regplot(x = feature, y = "medv", data = bostonDF, ax = ax[row][col])
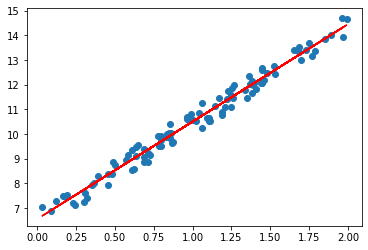
두 연속형 변수를 활용한 산점도나 회귀식 가능.
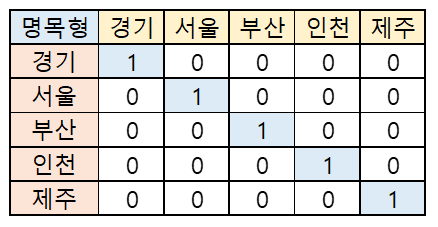
박스플롯 (x: 명목형, y: medv)
rm 3.4 chas 3.0 rad 0.4 zn 0.1 b 0.0 tax -0.0 age 0.0 indus 0.0 crim -0.1 lstat -0.6 ptratio -0.9 dis -1.7 nox -19.8
1 2 3 4 5 6 7
from sklearn.model_selection import train_test_split from sklearn.linear_model import LinearRegression # model
deftimer(func): """ 함수 실행 시간 확인 :param func: check할 함수 넣을거임 :return: 걸린 시간 """ defwrapper(*args, **kwargs): #현재 시간 time_start = time.time()
#decorated function 불러오기 result = func(*args, **kwargs) time_total = time.time() - time_start # print("{}, Total time is {: .2f} sec.".format(func.__name__, time_total))
return result return wrapper
가변 매개 변수 args(*)
함수를 정의할때 앞에 *가 붙어 있으면, 정해지지 않은 수의 매개변수를 받겠다는 의미
가변 매개변수는 입력 받은 인수를 튜플형식으로 packing 한다.
일반적으로 *args (arguments의 약자로 관례적으로 사용) 를 사용한다.
다른 매개 변수와 혼용가능
키워드 매개변수 kwargs(**)
함수에서 정의되지 않은 매개변수를 받을 때 사용되며, 딕셔너리 형식으로 전달.
일반 매개변수, 가변 매개변수와 함께 일는 경우 순서를 지켜야함 (일반>가변>키워드 순)
**kwargs (Keyword arguments의 약자로 관례적으로 사용 )
decorator 함수를 이용하여 시간 확인 함수 설정, 실행
1 2 3 4 5 6 7 8
@timer defcheck_time(num): time.sleep(num)
if __name__ == "__main__": check_time(1.5)
out
check_time, Total time is 1.50 sec.
관련 이론들을 아래에 적어 놓았다.
timestamp :python에서 time은 1970년 1월 1일 0시 0분 0초를 기준으로 경과한 시간을 나타냄