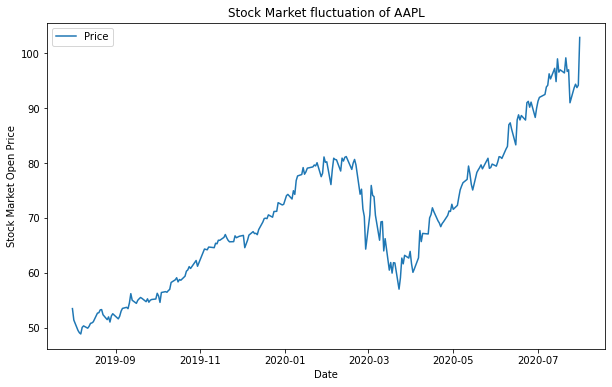
데이터 기능에서 유추된 결정규칙을 학습하여 대상 변수값을 예측 하는 모델을 만들기 위해 사용
종류
분류 트리
변수가 유한한 수의 값을 가지는 것, 클래스 출력
Leaf node는 클래스 라벨을 나타내고 가지는 클래스 라벨과 관련있는 특징들의 논리 곱을 나타낸다.
회귀트리
목표변수가 연속하는 값(일반적으로 실수 )을 가지는 트리
특정 의미를 가지는 실수값을 출력
의사결정 분석에서 결정트리는 시각적으로 명시적인 방법으로 과정을 보여준다.
결정트리의 학습
결정 트리의 학습 : 자료 집합을 적절한 분할기준 또는 분할 테스트에 따라 부분집합들로 나누는 과정
하향식 결정 트리 귀납법 (TDIDT_top-down induction of decision trees)
순환분할 방식으로 나눠진 자료의 부분집합에 재귀적으로 반복됨.
분할로 인해 더이상 새로운 예측값이 추가 되지 않거나 부분집합의 노드가 목표변수와 같은 값을 지닐대 까지 계속됨.
데이터 마이닝에서 결정트리
수학 적으로 표현됨
예를 들어 아래와 같은 데이터 마이닝에서의 결정 트리가 있다고 가정 해 보자.
( f{x},Y ) = (x_1, x_2, x_3, ..., x_k, Y)
종속 변수 Y는 분류를 통해 학습하고자 하는 목표 변수이며,
벡터 x는 { x_{1}, x_{2}, x_{3} } x_1, x_2, x_3 등의
입력 변수로 구성된다.
장점
1. 이해하기 쉬우며 시각화 가능
2. data 준비가 거의 필요하지 않음
3. 수치형, 범주형 data를 모두 처리 가능
4. multi-output problems를 다룰 수 있다.
5. a white box model을 사용 할 수 있다. (bool 가능)
6. 통계 검정을 사용하여 모형을 검증하기 때문에 모델의 신뢰성을 설명할 수 있다.
7. 생성된 데이터가 실제 모형에 의해 가정이 다소 위반되더라도 잘 수행된다.
단점
data 일반화가 잘 되지 못하면 복잡한 트리가 만들어짐 (과적합)
- 가지치기, 리프노드에 필요한 샘플 최소화, 트리 최대깊이 설정 으로 해결 가능
variation이 작은 경우 의사결정트리가 불안정 할 수 있다.
앙상블(ensemble) 내에서 의사결정 트리 사용으로 해결 가능.
실용적인 의사 결정 트리 학습 알고리즘은 각 노드에서 국소적으로 최적의 의사결정이 이루어지는 그리디 알고리즘과 같은 경험적 알고리즘을 기반으로 한다. 이러한 알고리즘은 전역 최적 의사 결정 트리를 반환한다고 보장할 수 없다.
이는 특징과 샘플이 교체와 함께 무작위로 샘플링되는 앙상블 학습기에서 여러 트리를 훈련시킴으로써 완화될 수 있다.
의사 결정 트리의 예측은 근사치이기 때문에 좋은 추정은 아닐 수 있다.
의사결정 트리의 최적화의 문제는 NP-complete로 잘 알려진 문제이다. 잘 모르겠다.
핵심 추진 요인은 생물학적 연구에서 처리량이 높은 기술 플랫폼의 확산이 증가하는 것으로, 체계적인 연구를 위해 수천 개의 조직과 유기체에 걸친 유전자, 단백질 및 기타 생물학적 부분에 대한 수백만 개의 데이터 포인트가 수집, 세척, 저장 및 통합될 수 있도록 한다.
이처럼 데이터가 풍부한 환경에서 생물학적(그리고 임상 샘플에 배치된 경우 생물의학) 연구의 미래는 데이터의 전략적 극대화에 있다고 해도 과언이 아니다.
오늘날의 기술 환경에서 데이터 과학 및 인공지능(AI)은 이미 비즈니스 및 금융과 같은 영역에서 혁신 동력으로 작용하고 있다. 여기서 데이터 과학자는 막후에서 작업하는 대신 데이터를 실질적인 통찰력으로 변환하는 역할을 담당하고 있다.
예를 들어, 인공지능 기반 알고리즘 거래와 금융 기술(FinTech)의 주식 추천 시스템, 엔지니어링의 자동화 엔진 설계, 시스템 유지보수 및 로봇공학 등이 있다. 최근의 데이터 폭발과 이에 따른 비즈니스, 금융 및 컴퓨팅과 같은 다른 분야의 데이터 과학의 발전을 감안할 때, 우리는 특히 생물학과 관련된 영역별 문제를 다루는 새로운 변형인 빠르고 방대한 양의 데이터 생성과 함께 데이터 과학이 등장할 것으로 예상한다. 이를 “바이오 데이터 과학” 이라고 한다.
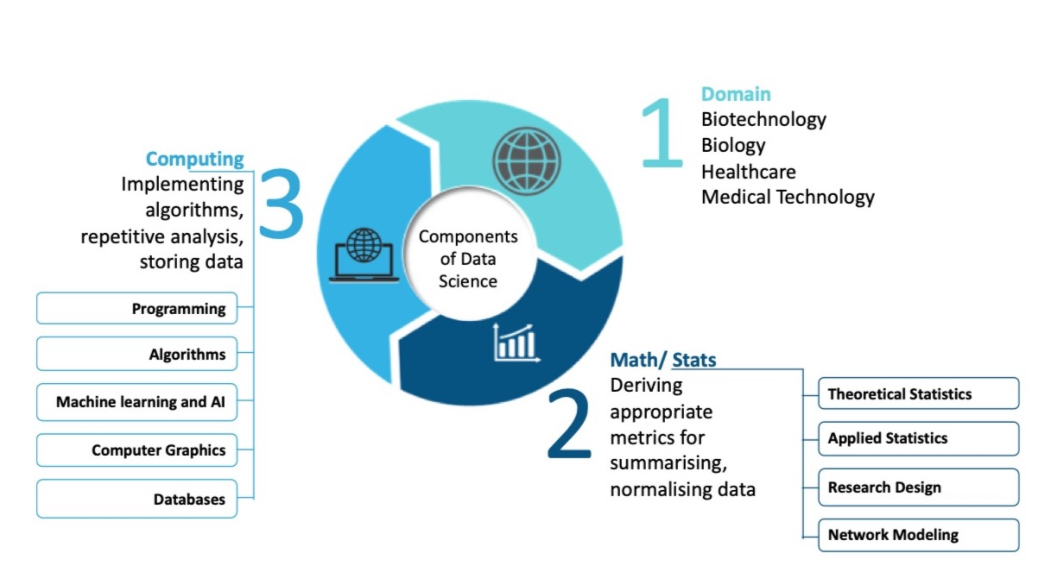
###BDS(BioData Science)에는 세 가지 핵심 분야가 있다.
생물학 영역: Biology
수학 및 통계 : mathematics (statistics)
컴퓨터 공학 : computer science
생물학 영역은 질병의 원인이나 유추된 바이오 마커의 진단 효용 이해와 같은 생물학적 기원에 대한 질문과 관련이 있다.
컴퓨터 과학 코어는 특히 분석할 데이터가 큰 경우 문제 해결을 위한 적절한 알고리즘 고안, 반복 처리 (예: 데이터의 큰 부분 집합에서 동일한 알고리즘 여러 번 실행) 및 데이터 저장 문제 해결과 관련이 있다.
수학 및 통계 핵심 영역은 데이터 요약, 정규화 및 모델링을 포함한 문제와 관련이 있다. 기술 및 탐색적 통계 데이터 분석이 BDS에만 국한된 것은 아니지만 (생물 통계의 필수 구성 요소이기도 하며, 더 낮은 정도로 생물 정보학이기도 함), BDS는 빅데이터에 AI/ML을 적용하는 것에 기초한 신흥 기술을 이용한 예측에 초점을 맞추고 있다.
###바이오 데이터 과학은 다른 과학 분야와 다르지 않은 탐구 과학이다. BDS는 단순히 기술(technology), 기계 학습(machine learning) 인공지능(AI)이 아니다.
인공지능이 여러분을 위해 그렇게 해주기를 바라는 대신, 사람의 강한 논리적 사고에 기초해야 한다. BDS가 궁극적으로 연구의 과학이라는 이런 점에서, 전형적인 과학적 조사와 다르지 않다.
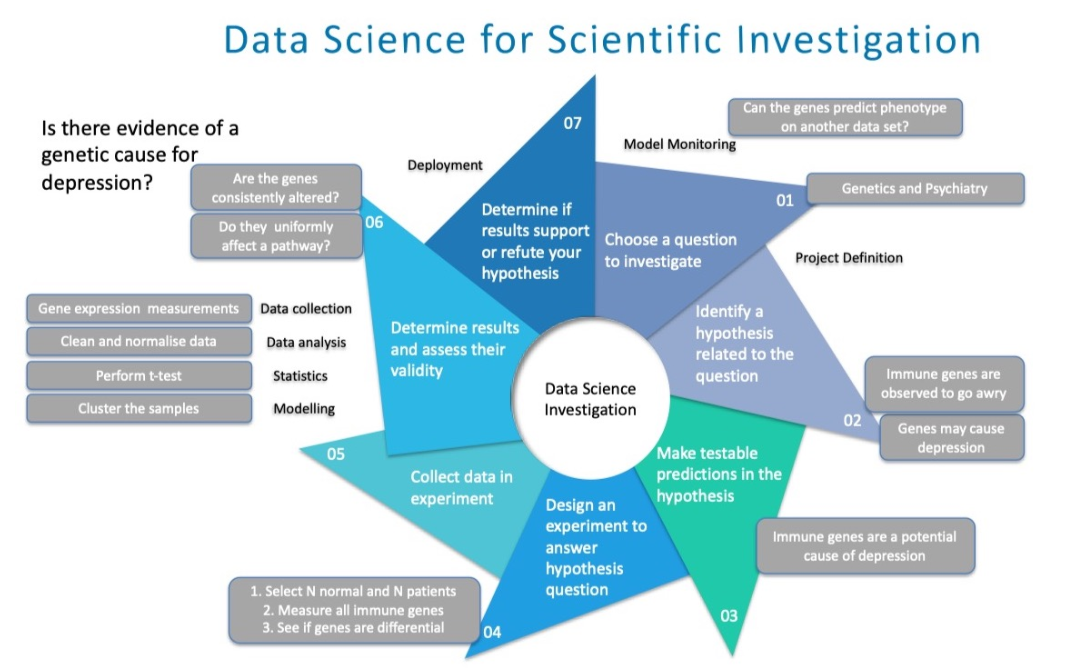
우리는 유전자 발현 변화가 정신 상태와 의미있게 상관되는지에 대한 질문에 답하도록 돕기 위해 다음의 7가지 단계를 사용할 수 있다.
가장 큰 차이점은 BDS는 낮은 처리량 또는 저전력 물리적 실험에 대한 강조를 줄이면서 의미 있는 데이터 조작 및 분석에 강력한 능력을 필요로 한다는 것이다.
데이터 과학은 다른 과학적 추구와 같은 과정으로 진행 된다.
- 조사할 질문을 먼저 선택
- 테스트 가능한 관련 가설을 확인함으로써 이 질문의 범위를 넓힘
- 가설에 답하기 위한 데이터를 얻기 위한 적절한 실험을 설계하고 현장 적용할
- 결과를 결정하고 그 타당성, 즉 데이터가 연구 질문에 답하는 데 적합한지 여부를 평가
- 마지막으로, 모델을 배치하고 연구 결과가 반복 가능한지 확인
###데이터 분석은 복잡한 다단계 프로세스이다. **BDS(BioData Science)**는 도전적인 분야이지만, 생물정보학이나 전산생물학과 비슷하게 어렵다.
생물학적 시스템을 측정하기 위한 기술적 플랫폼은 매우 정교하지만, 생물학적 시스템은 매우 복잡하다. 게다가 생물학적 실체를 측정하기 위해 개발된 기술적 도구는 생물학적 시스템의 구성요소가 변화하고 시간이 지남에 따라 자연스럽게 변화하는 동안 기술적 불확실성에 영향을 받는다. 바이오 빅 데이터는 이러한 문제에 대한 자연스러운 솔루션이 아니며 새로운 문제를 야기한다.
BDS 데이터는 매우 많은 수의 관측에서 보존된 패턴을 식별하는 과정과 같은 데이터 과학 노력을 촉진할 수 있지만, 적절한 분석 파이프라인이 개발될 경우에만 그렇게 할 수 있다. 이 작업은 하찮지 않다. 이러한 분석 파이프라인은 데이터 수집에서 시작하여 더 높은 수준의 생물학적 해석과 통찰력을 향한 계산 및 통계 평가를 통해 계속 이어지는 다양한 접근 방식의 엔드 투 엔드 통합으로 상상할 수 있다.
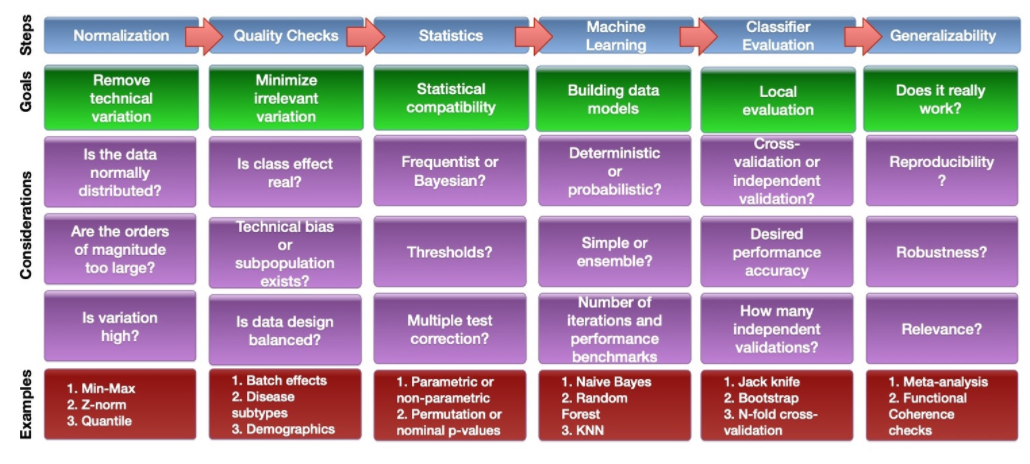
omics 데이터의 바이오 마커 분석을 위한 단순화된 파이프라인과 관련 주요 고려 사항은 다음과 같을 수 있다.
분석 파이프라인은 매우 유연해야 하며 연구 질문의 필요에 따라 변화해야 한다. 완벽한 지식이 부족하기 때문에 최적화와 재현성을 어느 정도 달성하기 위해 몇 단계를 왔다 갔다 반복하고 다듬는 것도 일반적이다.
예를 들어, 정규화 단계에서 두 개의 서로 다른 정규화 절차를 사용하여 매우 다르고 겹치지 않는 차등 유전자 세트를 발견했다고 가정 해 보자. 정규화 절차는 데이터에 대해 잘못된 가정을 하거나 잘못 구현되었을 수 있다. 표시된 주요 고려사항은 엄청나게 많다. 고려사항의 예와 함께 단계를 보여주는 목적은 각 단계마다 완벽한 시스템이나 파이프라인이 없지만, 각 의사결정 지점마다 이후 단계에 대한 결과를 갖는 많은 고려사항이 있음을 입증하는 것이다.
우리는 또한 특정 정규화 접근법이 다운스트림 통계 절차와 잘 작동하는지와 같은 호환성 문제나 특정 절차가 배치 효과 보정 알고리즘 및 일부 다중 시험 보정 방법과 관련된 과다 탈락 및 과다 첨가로 이어질 수 있는지 여부와 같은 문제를 걱정해야 한다.
일반적으로 좋은 결과를 보장하는 노선도나 표준 운영 절차는 없다는 점에서 BDS는 예술에 가까운 과학인 것이다.
[1103 학습] 시각화 연습 및 작성 코드 깃헙 블로그 및 깃헙에 올리기, 개인별로 공유
시각화 올릴 때, 전체 코드 올리지 마시고, 나눠서 올리세요. 설명 글 추가하시고여~ (예시 하단)
산점도: 산점도란 무엇인가? 언제 쓰는가? 코드 작성 및 간단 설명 박스플롯: 박스플롯이란 무엇인가? 언제 쓰는가? 코드 작성 및 간단 설명
오후 1시까지 1차로 한번 올려서 개인별로 공유해주세요. 홧팅요
Intro
python에서 visualiztion 하기 위해서는 많은 방법이 있다.
data Analist들은 시각화를 위해 많은 tool을 사용 하는데 우리는 Seaborn과 Matplotlib을 이용하여 시각화를 할 예정이다.
코드 기반(python)의 data visualiztion의 장점
여러 그래프 동시 작성 가능
기존의 코드 재활용성
데이터 그기의 제한이 없음 (RAM등의 제약조건 없을때)
Matplotlib 는 이미지 데이터와 정형 데이터(정적 그래프)를 시각화 할 수 있는데 나와 같은 비전공자들에게 시각화 문법이 조금 어렵다고 한다. 하지만 pandas data frame에서 쉽게 시각화 구현 하며, 통계(회귀선) 그래프 등을 쉽게 구현 할 수 있기 때문에 이를 배워야 한다.
seaborn의 경우 그래프가 예쁘게 나오지 않지만 비교적 간단한 코드로 시각화를 할 수 있다. 하지만, 세부 옵션을 수정 하고 싶다면 Matplotlib를 알아야 한다. 이는 내부 원리를 파악 할 수 없기 때문에 내가 감당하기 힘들다.
때문에 지금 단계에서는 Matplotlib과 seaborn의 장점을 적절하게 섞어서 시각화를 진행 해 보자.
아나콘다와 같은 IDE를 이용하여 작업 할 수도 있지만, 기본적으로 Import하여 편하게 사용 할 수 있다.
판다스의 이름은 계량 경제학에서 사용되는 용어인 **’PANel DAta’**의 앞 글자를 따서 지어졌다. 판다스는 R에서 사용되던 data.frame 구조를 본뜬 DataFrame이라는 구조를 사용하기 때문에, R의 data.frame에서 사용하던 기능 상당수를 무리없이 사용할 수 있도록 만들었다. 더욱이 파이썬이라는 접근성이 좋은 언어 기반으로 동작하기 때문에 데이터 분석을 파이썬으로 입문하는 사람들이 필수적으로 사용하는 라이브러리가 되었다.’
판다스 Import 하기
쥬피터 노트로 설치가 가능 하다고 하지만, 구글코랩이나 케글 노트에서는 Import하여 쉽게 사용한다.
1 2
import pandas as pd pd.__version__
pandas는 오픈소스로 누구나 무료로 이용 할 수 있고, Numpy, matplotlib등 다른 라이브러리들과 함께 쓰인다.
일반적으로 pandas는 pd로 import되기 때문에 pd.[function] 으로 써있으면 pandas 라이브러리를 이용한다고 생각 하면 된다.
Livraly의 경우 version 오류가 많이 있으므로, Import 해 주는 라이브러리는 version을 꼭 확인하여 오류에 대비 하도록 한다.
깃허브 노트북과 데스크탑 두군데서 깃허브를 동시에 사용하고 싶은 분들은 아래 코드 확인해서 해보세요.
이 때, 깃헙 blog 저장소 삭제할 필요가 없어요~
1 2 3 4 5 6 7 8 9 10 11 12
$ hexo init myblog # 여기는 각자 소스 레포 확인 $ cd myblog $ git init $ git remote add origin https://github.com/rain0430/myblog.git # 각자 소스 레포 주소 $ git pull --set-upstream origin main # 에러 발생 $ git clean -d -f $ git pull --set-upstream origin main # 에러 발생 안함 / 소스 확인 $ npm install $ hexo clean $ hexo generate $ hexo server
# 한 줄 주석 처리 """ 여러 줄 주석 예제 동일한 따옴표(큰따옴표 혹은 작은 따옴표) 세 개와 세 개 사이에는어떠한 내용, 몇 줄이 들어가더라도 모두 주석으로 처리된다. """ print("Hello, world!")
Hello, world!
변수의 종류
1 2
num_int = 1 print(type(num_int))
<class 'int'>
1 2
num_float = 0.2 print(type(num_float))
<class 'float'>
1 2
bool_true = True print(type(bool_true))
<class 'bool'>
1 2
none_x = None print(type(none_x))
<class 'NoneType'>
사칙 연산
1 2 3 4 5 6 7 8 9
a = 3 b = 2 print('a + b = ', a+b) print('a - b = ', a-b) print('a * b = ', a*b) print('a / b = ', a/b) print('a // b = ', a//b) print('a % b = ', a%b) print('a ** b = ', a**b)
a + b = 5
a - b = 1
a * b = 6
a / b = 1.5
a // b = 1
a % b = 1
a ** b = 9
1 2 3 4 5 6 7 8 9
c = 3.0 d = 2.0 print('c + d =', c+d) print('c - d =', c-d) print('c * d =', c*d) print('c / d =', c/d) print('c // d =', c//d) print('c % d =', c%d) print('c ** d =', c**d)
c + d = 5.0
c - d = 1.0
c * d = 6.0
c / d = 1.5
c // d = 1.0
c % d = 1.0
c ** d = 9.0
a = [] # 빈 리스트 a_func = list() #list()함수로도 빈 리스트를 만들 수 있다. b = [1] # 숫자도 요소가 될 수 있다. c = ['apple'] # 문자열도 요소가 될 수 있다 d = [1, 2, ['apple']] # 리스트 안에 리스트를 요소로 넣을 수 있다.
print(a) print(a_func) print(b) print(c) print(d)
[]
[]
[1]
['apple']
[1, 2, ['apple']]
1 2 3 4 5 6
a = [1, 2, 3] # index [[0], [1], [2]] print(a[0]) # 첫번째 요소 print(a[1]) # 두번째 요소 print(a[2]) # 세번째 요소 print(a[-1])
1
2
3
3
1 2 3 4 5 6 7
a = [['apple','banana','cherry'], 1]
print(a[0]) # 리스트 내의 리스트 print(a[0][0]) # 리스트 내의 리스트의 첫번째 문자열 print(a[0][0][3]) # 리스트 내의 리스트의 첫번째 문자열 'apple' 중 첫번째 인덱스 print(a[0][1]) # 리스트 내의 리스트의 두번째 문자열 print (a[0][2])
['apple', 'banana', 'cherry']
apple
l
banana
cherry
1 2 3 4 5 6 7 8 9 10 11 12 13
a = [1,2,3,4,5,6,7,8,9,10]
b = a[:4] # 인덱스 0부터 3까지 c = a[1:4] # 인덱스 1부터 3까지 d = a[0:7:2] # 인덱스 0부터 6까지 인덱스 2씩 건너 띄우기 e = a[::-1] # 리스트 a의 역순 f = a[::2] # 리스트 전체구간에서 인덱스 2씩 건너띄우기
print("a[:4]", b) print("a[1:4]", c) print("a[0:7:2]", d) print("a[::-1]", e) print("a[::2]", f)
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-38-1624da3f09a9> in <module>()
1 b = [4,3,2,'a']
2
----> 3 b.sort()
4 print(b)
TypeError: '<' not supported between instances of 'str' and 'int'
튜플
1 2 3 4 5 6 7 8 9 10 11
tuple1 = (0) # 끝에 콤마(,)를 붙이지 않았을 때 tuple2 = (0,) # 끝에 콤마(,)를 붙여줬을 때 tuple3 = 0,1,2
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-41-c41b8ecfc68f> in <module>()
1 a = (0,1,2,3,'a')
----> 2 del a['a']
TypeError: 'tuple' object does not support item deletion
1 2
a = (0,1,2,3,'a') a[1]='t'
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-42-04fb068f82e0> in <module>()
1 a = (0,1,2,3,'a')
----> 2 a[1]='t'
TypeError: 'tuple' object does not support item assignment