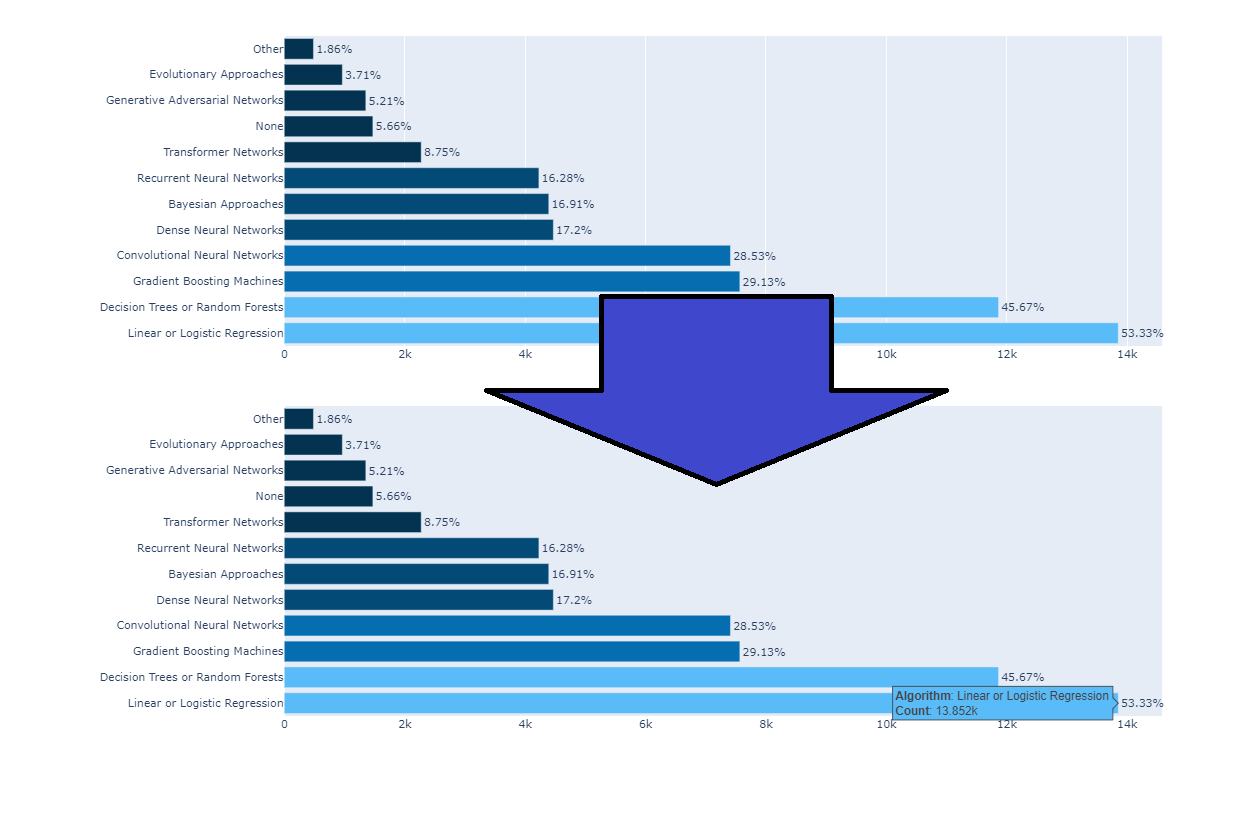
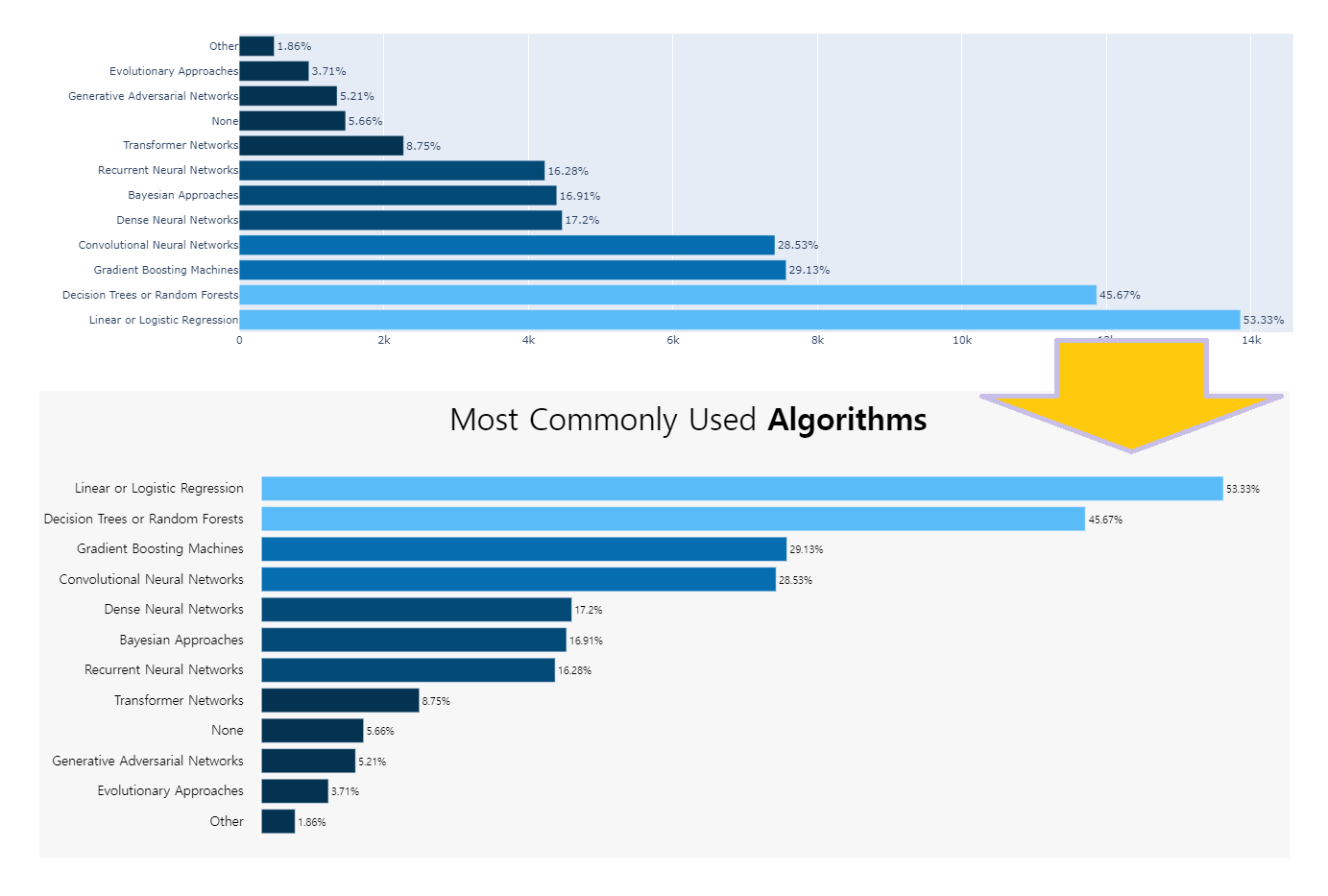
kaggle in Africa_barH(1-1)
1. Figure
Helper functions
Kgg_Africa 에서는 python 문법 중에서 함수를 만드는 def 을 이용하여 plot들을 정의 해 놓았다.
def 함수명(매개변수):
<수행할 문장1>
<수행할 문장2>
...
ref. python_Function/Ko.
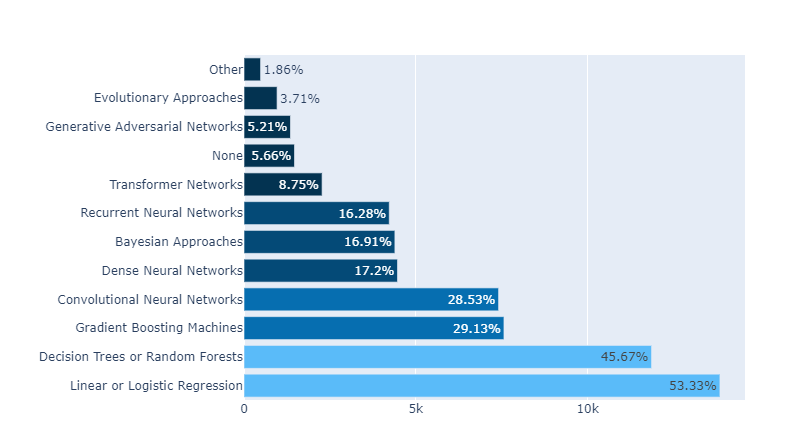
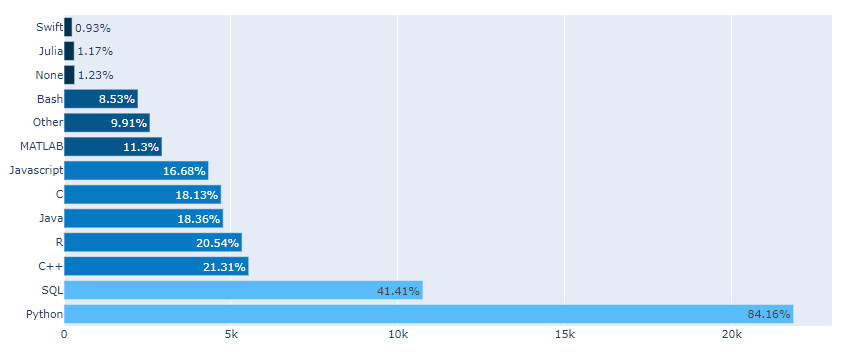
1.1 horizontal bar graphs
다음 results plot 을 뜯어보며 bar-H를 해석 해 보자.
- How does Africa compares with rest of the world?
- (Region(Q3)) 응답자 수(Africa/전체, 2021): bar-H
먼저, hBar는 다음과 같이 정의 되었다.
그동암 bar-H에대한 많은 부분을 공부 했으므로 간단히 함수를 중심으로 뜯어 보자.
1 | def plotly_hBar(df, q, title, height=400,l=250,r=50,b=50,t=100,): |
- def plotly_hBar(df, q, title, height=400,l=250,r=50,b=50,t=100,)
- 함수 plotly_hBar의 정의
- df, q, title등의 변수를 선언하고 값을 정해줌.
- fig 정의
1
2
3
4
5
6
7
8
9
10
11
12fig = px.histogram(df.iloc[1:],
y=q,
orientation='h',
width=700,
height=height,
histnorm='percent',
color='region',
color_discrete_map={
"Africa": "gold", "World": "salmon"
},
opacity=0.6
)
- plotly.express.histogram()
- plotly의 express Library를 이용하여 histogram을 그려본다.
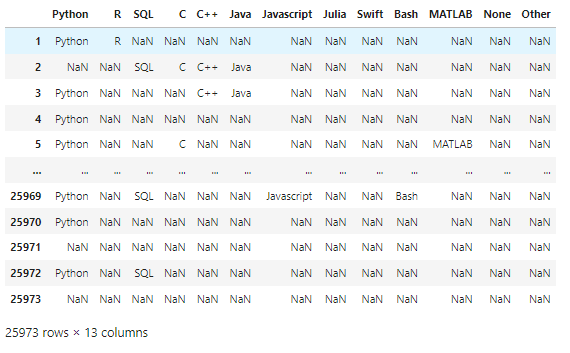
- df.iloc[1:]
- dataframe으로 iloc을 이용하여 컬럼을 가져옴 1행에서부터 끝까지
- y= q,
- 나중에 q변수만 정해서 넣어주면 G가 그려진다.
- orientation= ‘h’,
- orientation이 h일땐, x
- orientation이 v일땐, y
- 를 하라고 공식문서에 써있는데 왜 얘는 이랬는지 알 수 없음 + Histogram plot ???.
- height = ‘height’,
- plot의 높이 지정 height=400이라고 함수 정의때 이미 지정 됨.
- color = ‘region’,
- 색은 region이라는 변수가 어떤것이냐에 따라 달라짐
- color_discrete_map={“Africa”: “gold”, “World”: “salmon”},
- dictionary처럼 Indexing 해 줌.
- opacity = 0.6
- 불 투명함의 정도 (0~1, flot)
- df.iloc[1:]
- plotly의 express Library를 이용하여 histogram을 그려본다.
color_discrete_map 과
color_discrete_sequence 의 차이
dict with str keys and str values (default {}) ,
(list of str)
- fig.update_layout()
1
2
3
4
5
6
7
8
9
10
11
12
13
14fig.update_layout(title=title,
font_family="San Serif",
bargap=0.2,
barmode='group',
titlefont={'size': 28},
paper_bgcolor='#F5F5F5',
plot_bgcolor='#F5F5F5',
legend=dict(
orientation="v",
y=1,
yanchor="top",
x=1.250,
xanchor="right",)
).update_yaxes(categoryorder='total ascending')
fig.update_layout() :
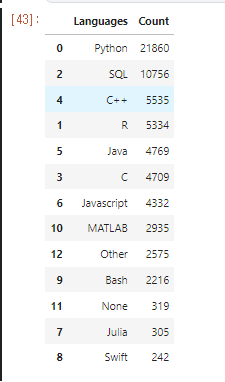

.png)