1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
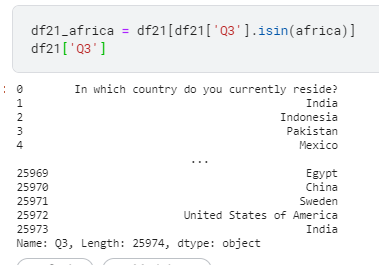
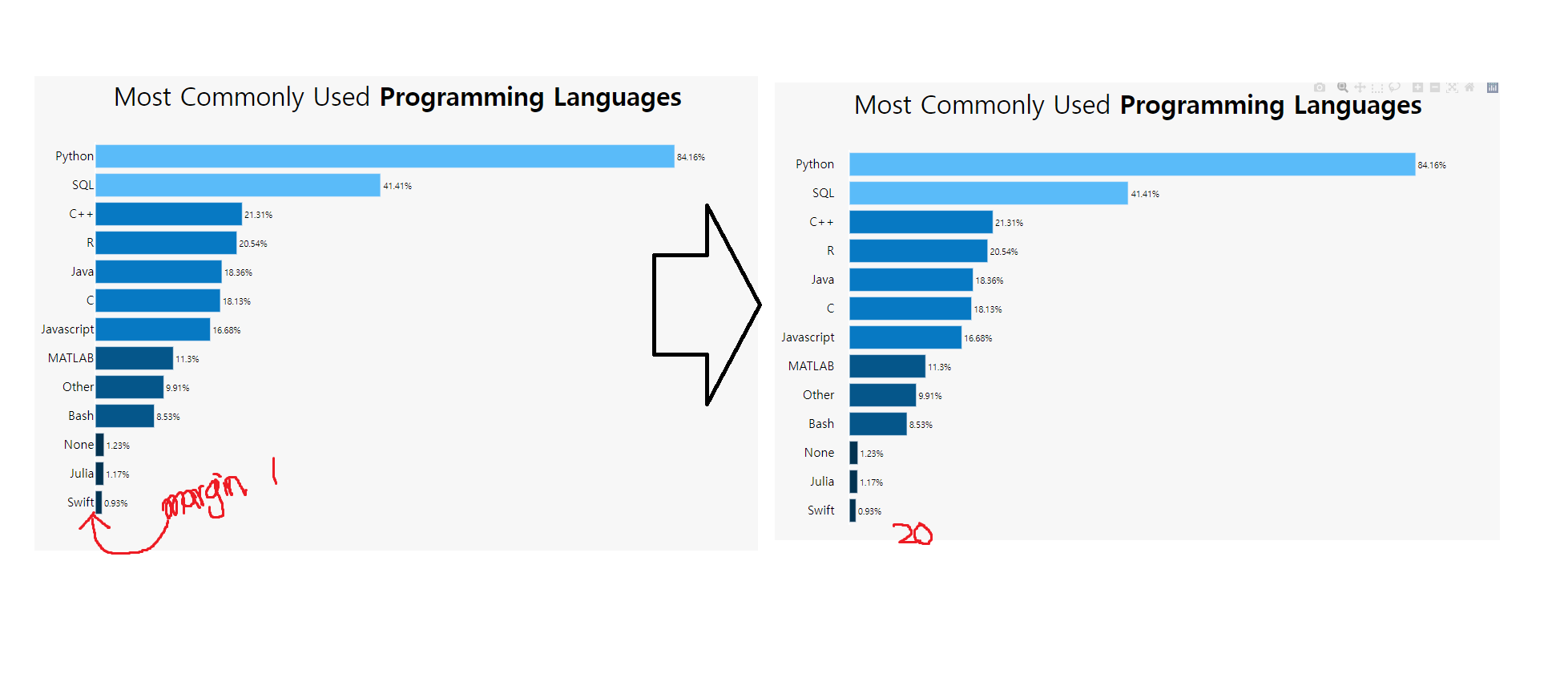
| def plotly_hBar(df, q, title, height=400,l=250,r=50,b=50,t=100,):
fig = px.histogram(df.iloc[1:],
y=q,
orientation='h',
width=700,
height=height,
histnorm='percent',
color='region',
color_discrete_map={
"Africa": "gold", "World": "salmon"
},
opacity=0.6
)
fig.update_layout(title=title,
font_family="San Serif",
bargap=0.2,
barmode='group',
titlefont={'size': 28},
paper_bgcolor='#F5F5F5',
plot_bgcolor='#F5F5F5',
legend=dict(
orientation="v",
y=1,
yanchor="top",
x=1.250,
xanchor="right",)
).update_yaxes(categoryorder='total ascending')
fig.update_traces(marker_line_color='black',
marker_line_width=1.5)
fig.update_layout(yaxis_title=None,yaxis_linewidth=2.5,
autosize=False,
margin=dict(
l=l,
r=r,
b=b,
t=t,
),
)
fig.update_xaxes(showgrid=False)
fig.update_yaxes(showgrid=False)
fig.show()
|

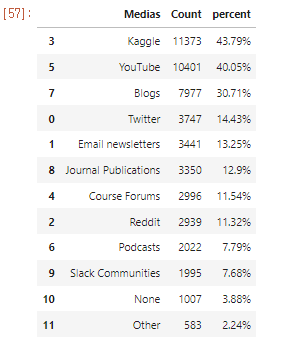
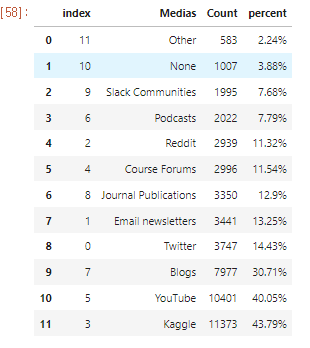
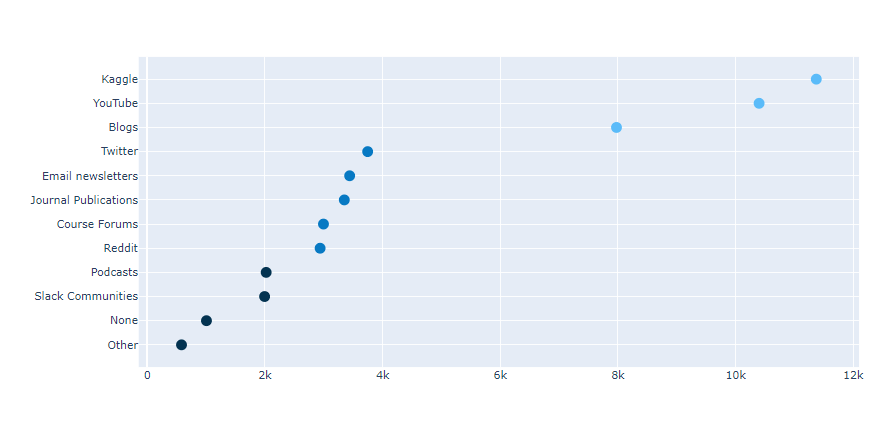
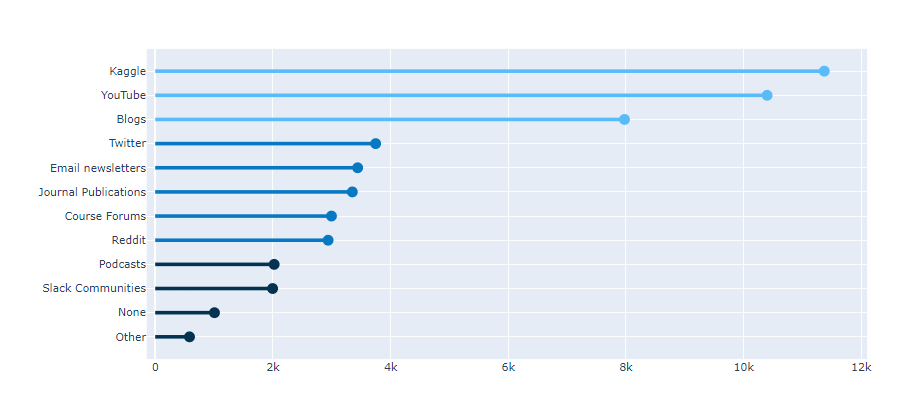
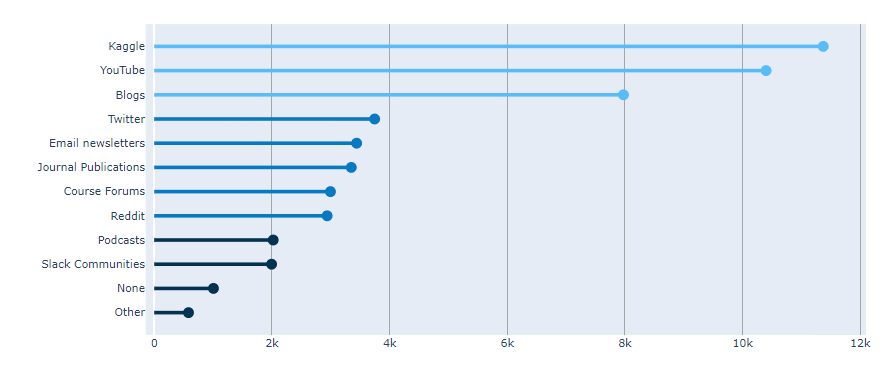
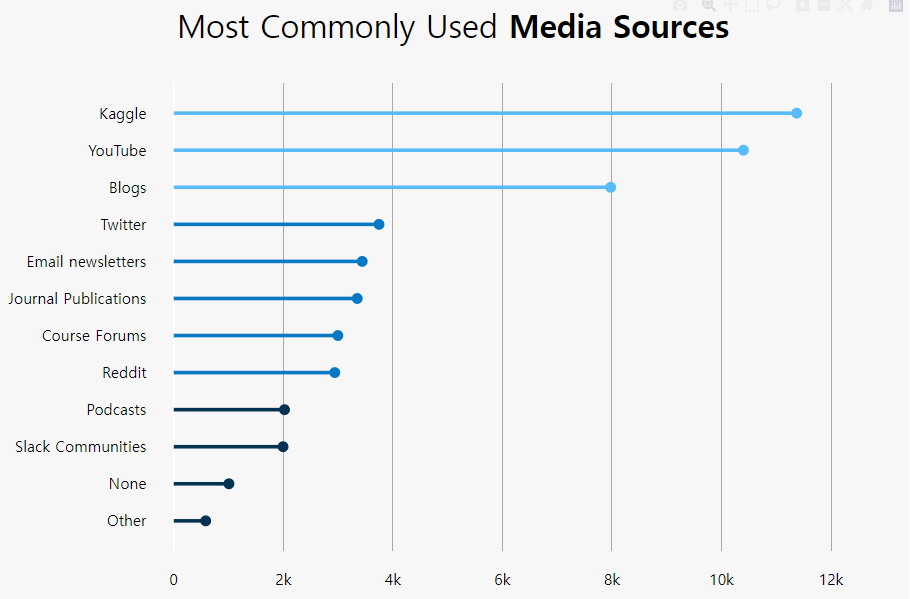
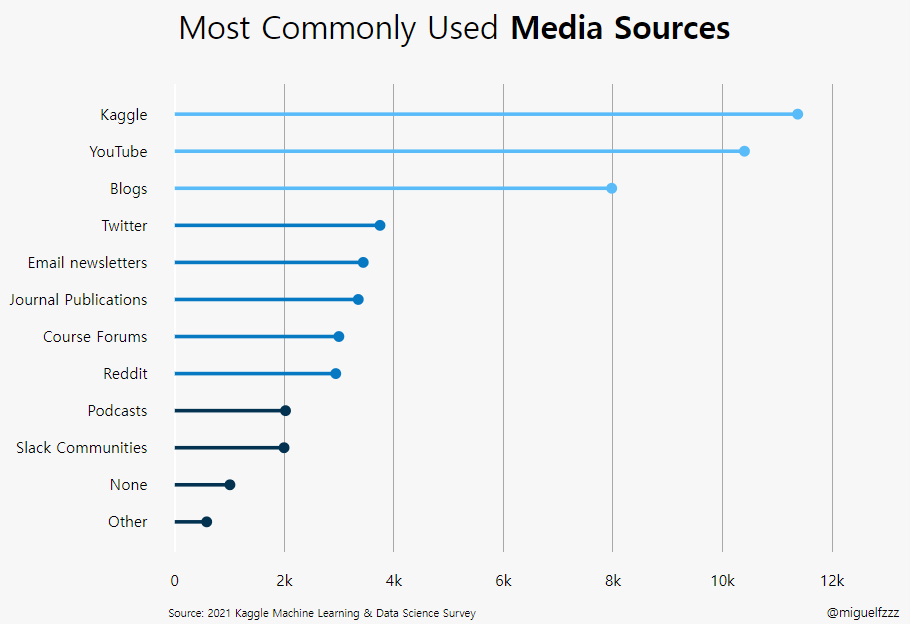
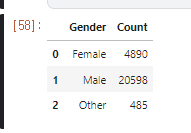
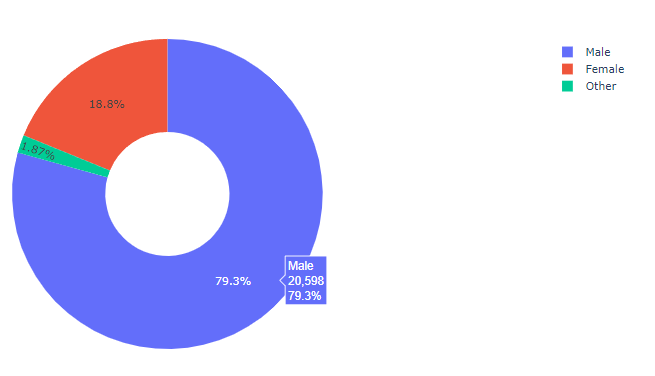
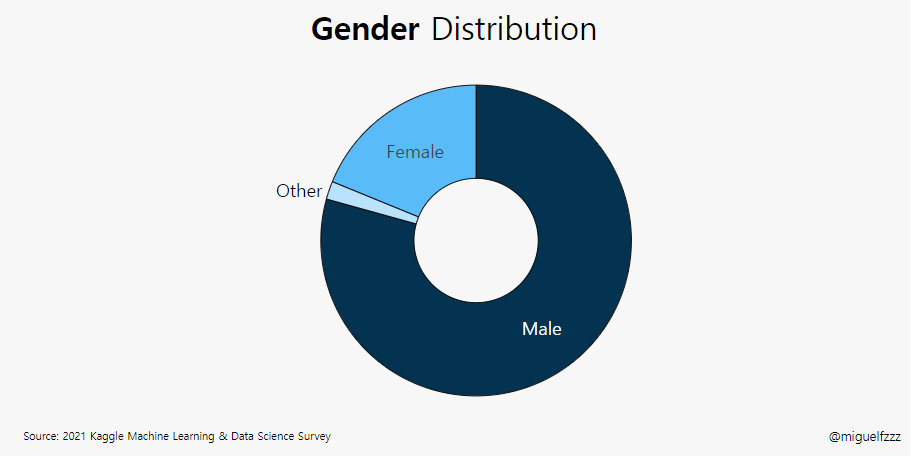

.png)