1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
|
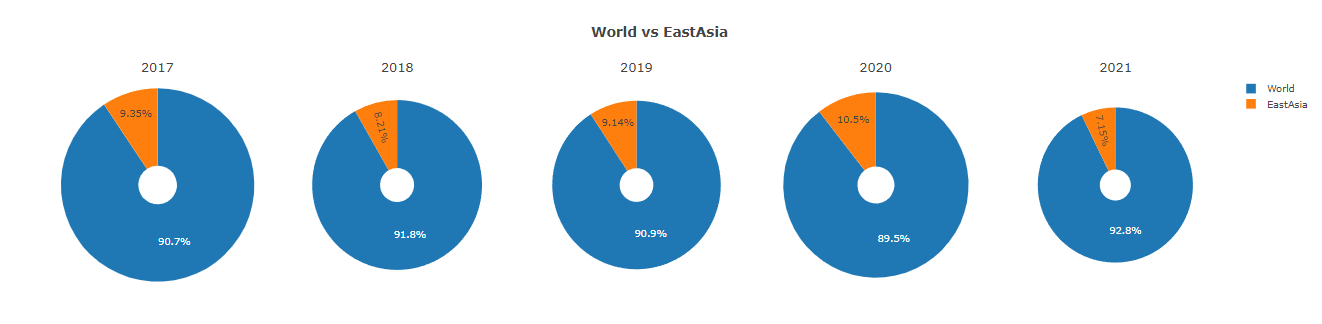
fig = make_subplots(rows=1, cols=5,
specs=[[{'type':'domain'}, {'type':'domain'}, {'type':'domain'}, {'type':'domain'}, {'type':'domain'}]],
subplot_titles=("2017", "2018", "2019", "2020", "2021"))
fig.add_trace(go.Pie(labels=total21['type'],
values=total21['respodents'], name="2021", scalegroup='one'),
1, 1)
fig.add_trace(go.Pie(labels=total20['type'],
values=total20['respodents'], name="2020", scalegroup='one'),
1, 2)
fig.add_trace(go.Pie(labels=total19['type'],
values=total19['respodents'], name="2019", scalegroup='one'),
1, 3)
fig.add_trace(go.Pie(labels=total18['type'],
values=total18['respodents'], name="2018", scalegroup='one'),
1, 4)
fig.add_trace(go.Pie(labels=total17['type'],
values=total17['respodents'], name="2017", scalegroup='one'),
1, 5)
fig.update_traces(hole=.2, hoverinfo="label+percent+name")
fig.update_layout(
title_text="<b>World vs EastAsia</b>",
)
fig.show()
|