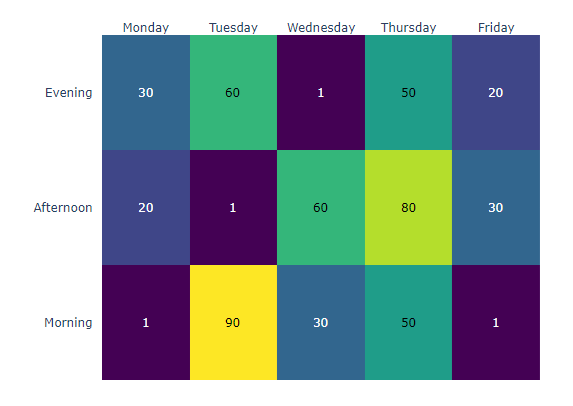
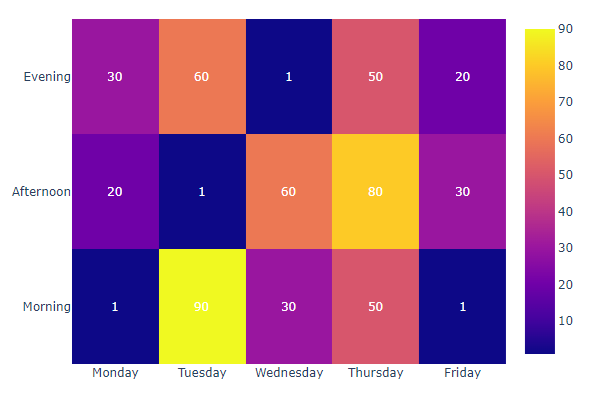
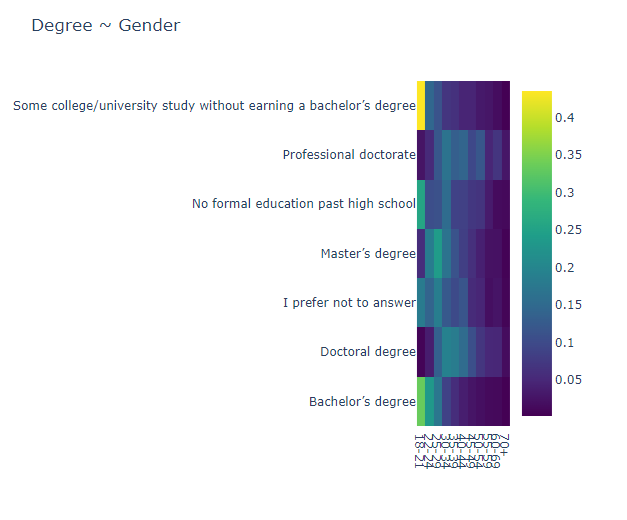
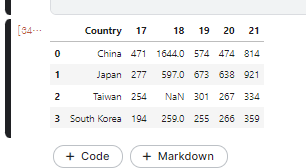
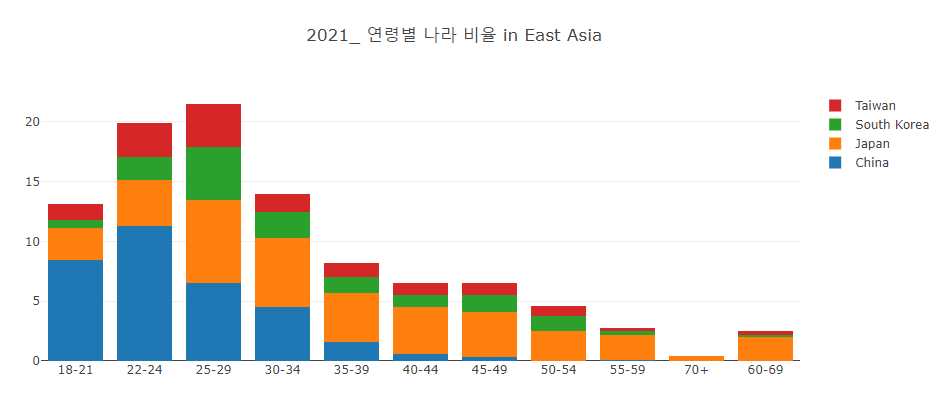
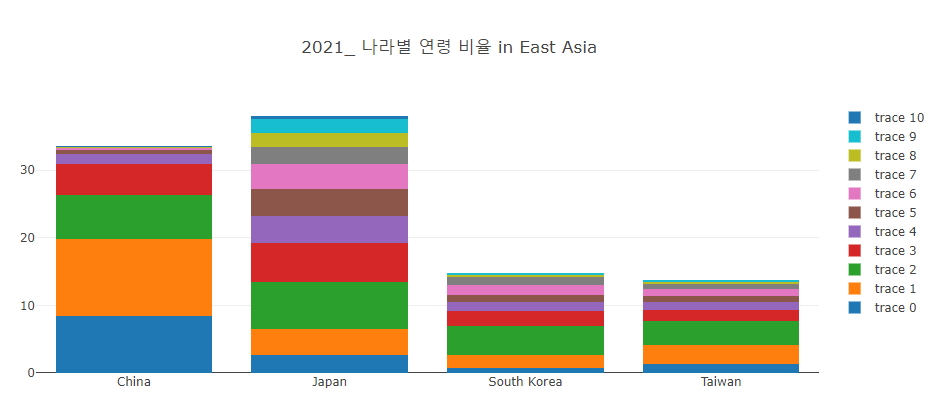
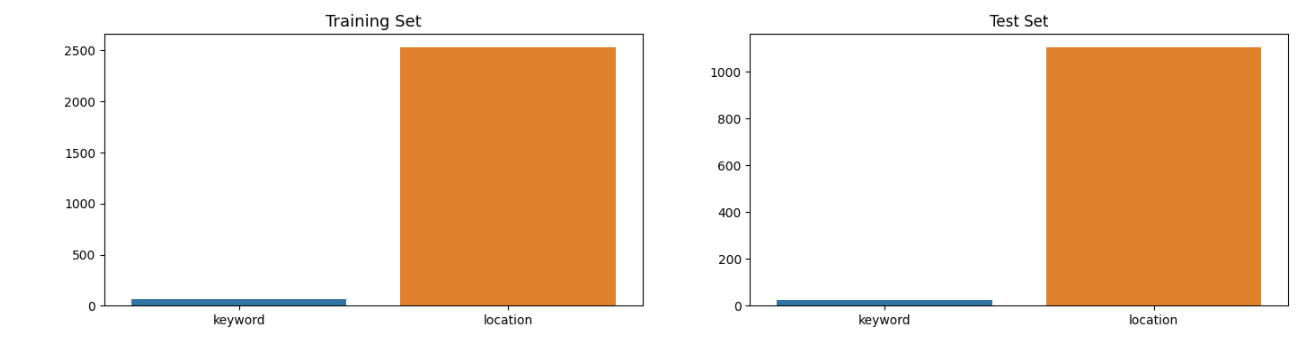
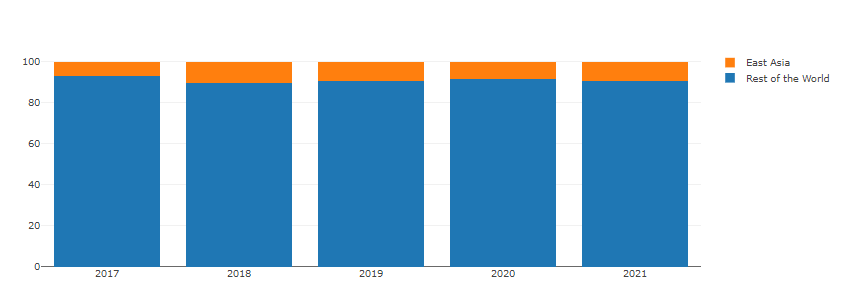1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
|
Data_Analyst =['Data Analyst','Data Miner,Information technology','Data Miner',
'Predictive Modeler','Information technology, networking, or system administration',
'A business discipline (accounting, economics, finance, etc.)', 'Business Analyst', 'Humanities',
'Statistician', 'Mathematics or statistics', 'Medical or life sciences (biology, chemistry, medicine, etc.)',
'Physics or astronomy', 'Research Scientist', 'Researcher', 'Social sciences (anthropology, psychology, sociology, etc.)',
'Humanities (history, literature, philosophy, etc.)']
Data_Scientist =['Data Scientist', 'Environmental science or geology',
'Machine Learning Engineer', 'Scientist/Researcher']
Developer=['Developer Relations/Advocacy','Data Engineer','Engineer','Engineering (non-computer focused)',
'Programmer','Software Engineer', 'Computer Scientist','Computer science (software engineering, etc.)',
'Fine arts or performing arts','Product Manager', 'Software Developer/Software Engineer',
'Product/Project Manager','Program/Project Manager','DBA/Database Engineer']
Not_Employeed =['Currently not employed', 'Not employed', 'Student']
Others = ['I never declared a major', 'Other']
df21job_Ea = df21_Ea.loc[:,['Q3','Q5']].reset_index().rename(columns={'index':'job', 'Q5':'2021'}).fillna('Other')
df20job_Ea = df20_Ea.loc[:,['Q3','Q5']].reset_index().rename(columns={'index':'job', 'Q5':'2020'}).fillna('Other')
df19job_Ea = df19_Ea.loc[:,['Q3','Q5']].reset_index().rename(columns={'index':'job', 'Q5':'2019'}).fillna('Other')
df18job_Ea = df18_Ea.loc[:,['Q3','Q5']].reset_index().rename(columns={'index':'job', 'Q5':'2018'}).fillna('Other')
df17job_Ea = df17_Ea.loc[:,['Country','CurrentJobTitleSelect']].reset_index().rename(columns={'index':'job', 'CurrentJobTitleSelect':'2017'}).fillna('Other')
df21job_Ea.value_counts('2021')
df21job_Ea['JOB']=["Data Analyst" if x in Data_Analyst
else "Data Scientist" if x in Data_Scientist
else "Data Engineer" if x in Developer
else "NotEmployeed" if x in Not_Employeed
else "Others"
for x in df21job_Ea['2021']]
df21job_Ea.value_counts('JOB')
df20job_Ea.value_counts('2020')
df20job_Ea['JOB']=["Data Analyst" if x in Data_Analyst
else "Data Scientist" if x in Data_Scientist
else "Data Engineer" if x in Developer
else "NotEmployeed" if x in Not_Employeed
else "Other"
for x in df20job_Ea['2020']]
df20job_Ea[['2020','JOB']]
df19job_Ea.value_counts('2019')
df19job_Ea['JOB']=["Data Analyst" if x in Data_Analyst
else "Data Scientist" if x in Data_Scientist
else "Data Engineer" if x in Developer
else "NotEmployeed" if x in Not_Employeed
else "Other"
for x in df19job_Ea['2019']]
df19jobTest = df19job_Ea.loc[df19job_Ea.JOB == 'Other']
df19jobTest['2019'].value_counts()
df18job_Ea.value_counts('2018')
df18job_Ea['JOB']=["Data Analyst" if x in Data_Analyst
else "Data Scientist" if x in Data_Scientist
else "Data Engineer" if x in Developer
else "NotEmployeed" if x in Not_Employeed
else "Other"
for x in df18job_Ea['2018']]
df18jobTest = df18job_Ea.loc[df18job_Ea.JOB == 'Other']
df18jobTest['2018'].value_counts()
df17job_Ea.value_counts('2017')
df17job_Ea['JOB']=["Data Analyst" if x in Data_Analyst
else "Data Scientist" if x in Data_Scientist
else "Data Engineer" if x in Developer
else "NotEmployeed" if x in Not_Employeed
else "Other"
for x in df17job_Ea['2017']]
df17jobTest = df17job_Ea.loc[df17job_Ea.JOB == 'Other']
df17jobTest['2017'].value_counts()
df21jobTest = df21job_Ea.loc[df21job_Ea.JOB == 'Other']
df21jobTest['2021'].head()
df21job_Ea.value_counts('JOB')
dfjob21 =df21job_Ea.groupby(['Q3','JOB']).size().reset_index().rename(columns = {0:"Count"}).rename(columns={'Q3':'country', 'JOB':'2021'})
dfjob20 =df20job_Ea.groupby(['Q3','JOB']).size().reset_index().rename(columns = {0:"Count"}).rename(columns={'Q3':'country', 'JOB':'2020'})
dfjob19 =df19job_Ea.groupby(['Q3','JOB']).size().reset_index().rename(columns = {0:"Count"}).rename(columns={'Q3':'country', 'JOB':'2019'})
dfjob18 =df18job_Ea.groupby(['Q3','JOB']).size().reset_index().rename(columns = {0:"Count"}).rename(columns={'Q3':'country', 'JOB':'2018'})
dfjob17 =df17job_Ea.groupby(['Country','JOB']).size().reset_index().rename(columns = {0:"Count"}).rename(columns={'Country':'country', 'JOB':'2017'})
|