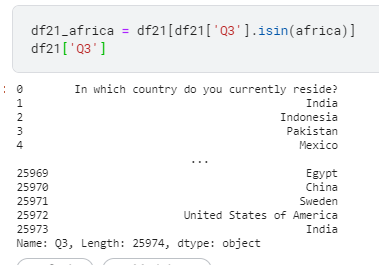
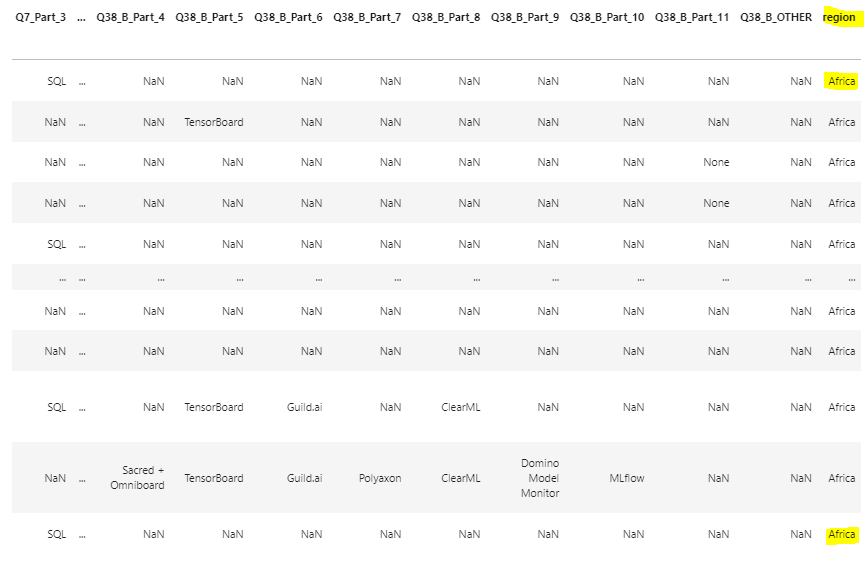
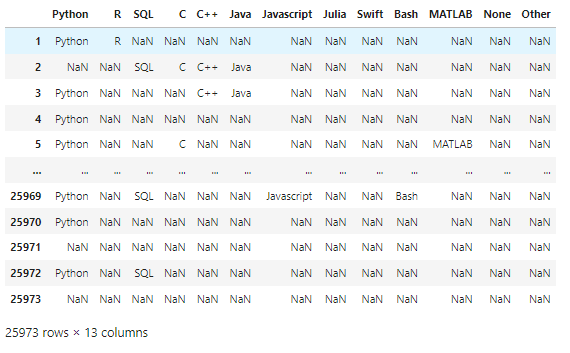
df21_africa = df21[df21['Q3'].isin(africa)] df21_world = df21[~df21['Q3'].isin(africa )] df21['region']=["Africa"if x in africa else"World"for x in df21['Q3']]
df20_africa = df20[df20['Q3'].isin(africa)] df20_world = df20[~df20['Q3'].isin(africa )] df20['region']=["Africa"if x in africa else"World"for x in df20['Q3']]
df19_africa = df19[df19['Q3'].isin(africa)] df19_world = df19[~df19['Q3'].isin(africa)] df19['region']=["Africa"if x in africa else"World"for x in df19['Q3']]
df18_africa = df18[df18['Q3'].isin(africa)] df18_world = df18[~df18['Q3'].isin(africa)] df18['region']=["Africa"if x in africa else"World"for x in df18['Q3']]
df17_africa = df17[df17['Country'].isin(africa)] df17_world = df17[~df17['Country'].isin(africa )] df17['region']=["Africa"if x in africa else"World"for x in df17['Country']]
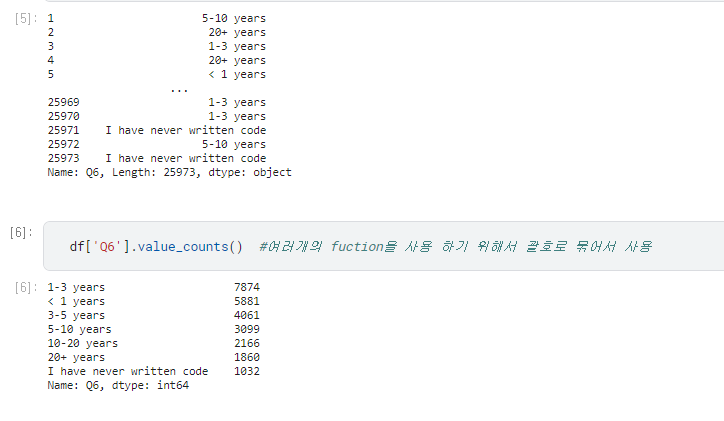
‘africa’라는 배열을 만들어 df를 새로 정의
17’~21’까지 같은 내용이므로 21’의 내용만으로 정리
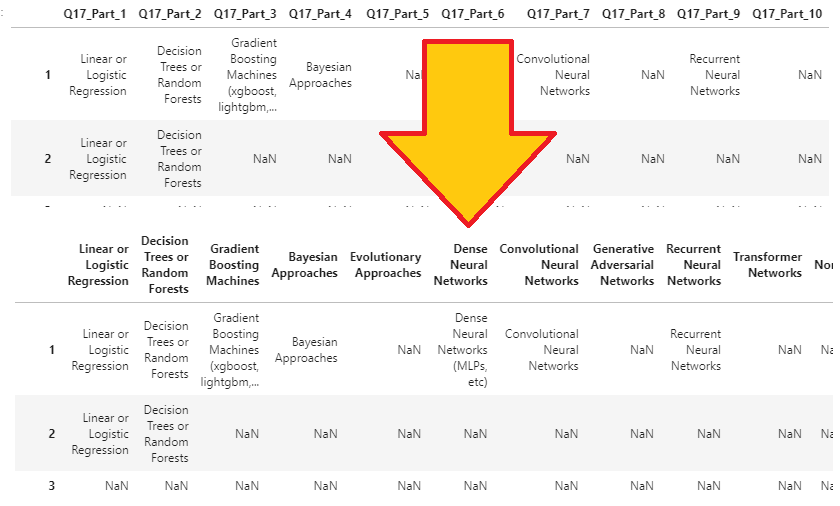
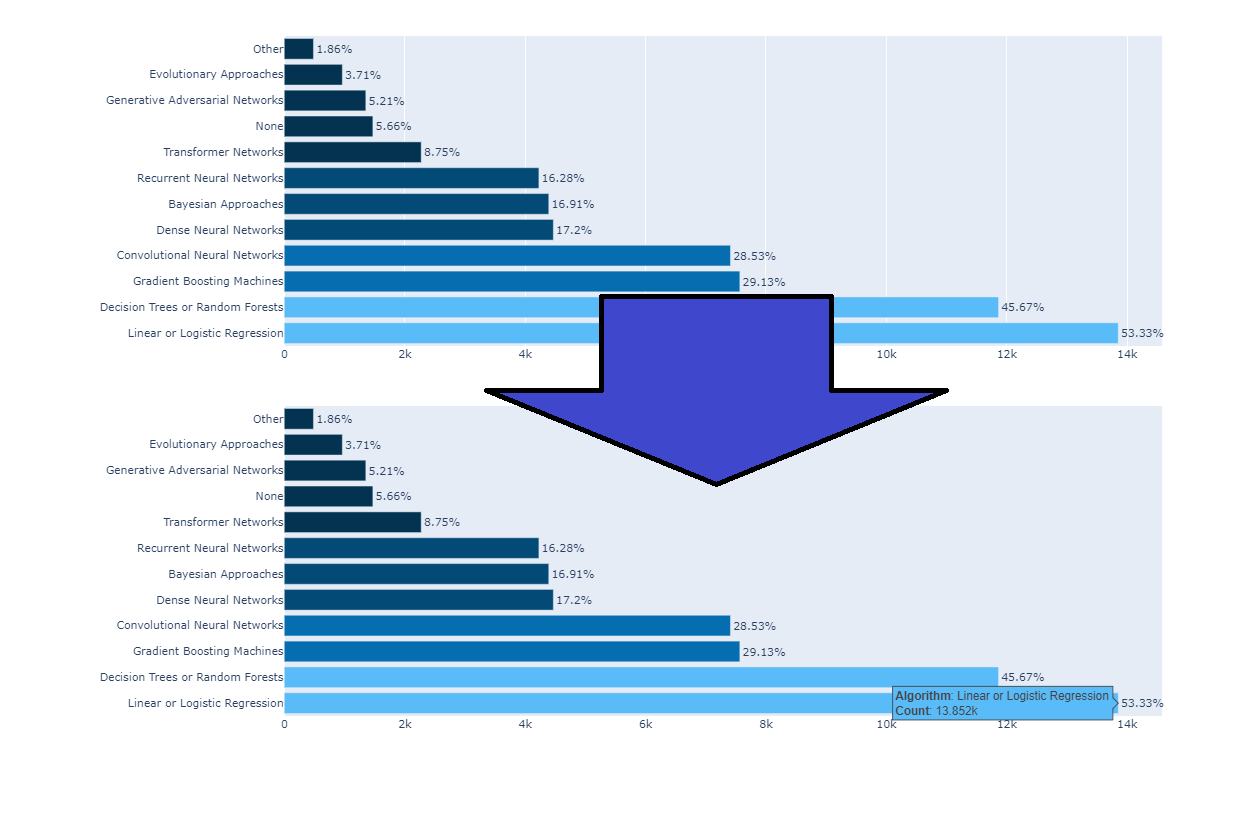
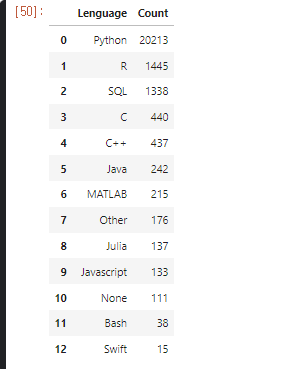
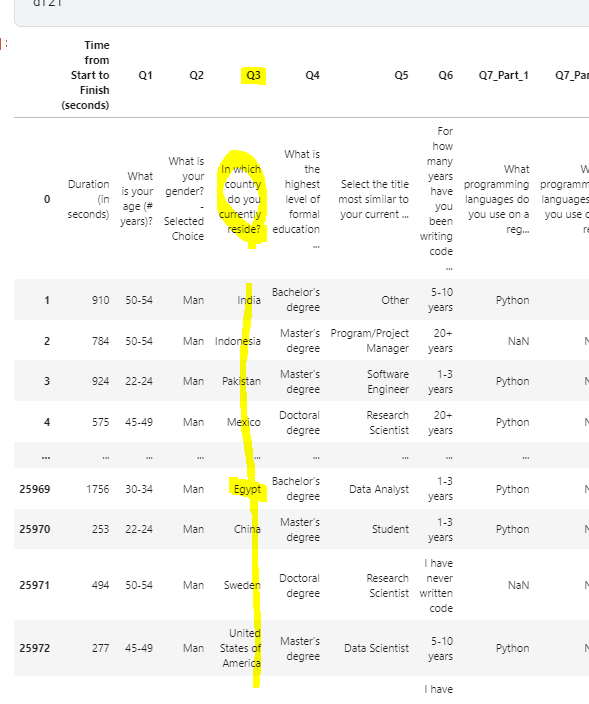
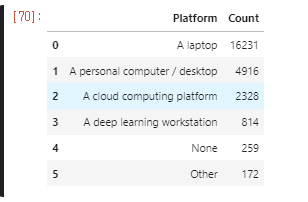
0> df21 data 확인
1> df21[‘Q3’]의 내용은 당신의 나라는 어디 입니까?
2> 따라서 “ df21[‘Q3’].isin(africa) “ 코드의 의미는 Q3의 대답이 africa 이면 True 반환.
3> 결론적으로 Q3의 대답이 Africa[]인 모든 대답을 추출 하게 된다.
4> 반대로 dfworld의 경우 ~ ( not )을 사용하여 Q3이 false인 data frame을 추출 할 수 있는것.
1.2.3 region column을 추가
1
df21['region']=["Africa"if x in africa else"World"for x in df21['Q3']]
df21 dataframe에 Region이라는 column 을 추가해 보자.
region 컬럼에 들어갈 값은
List의 끝까지 반복하되, 만약 df21[‘Q3’]의 값이 africa에 해당하면 “Africa”, 그 밖의 경우는 world를 입력해라.
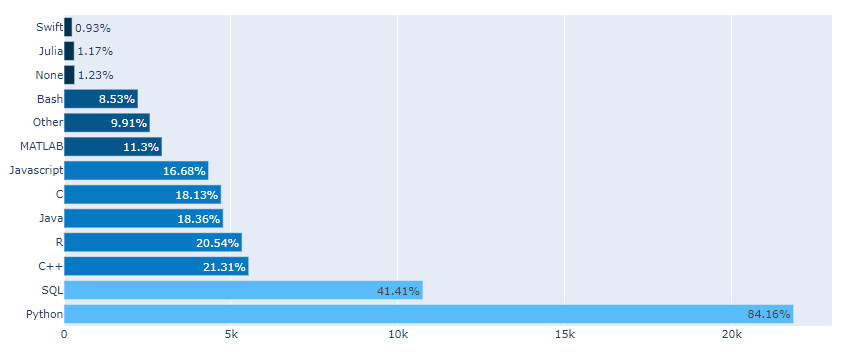
cliponaxis – Text node를 아래 축에 고정 할지 아닐지 결정 text node를 축 라인과 체크라벨 위에 보여주기위해서는 x축Layer와 y축 layer 설정을 해 주어야 한다.
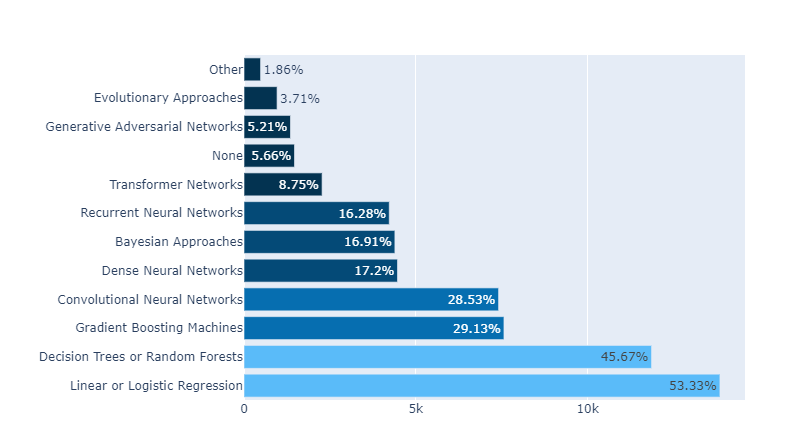
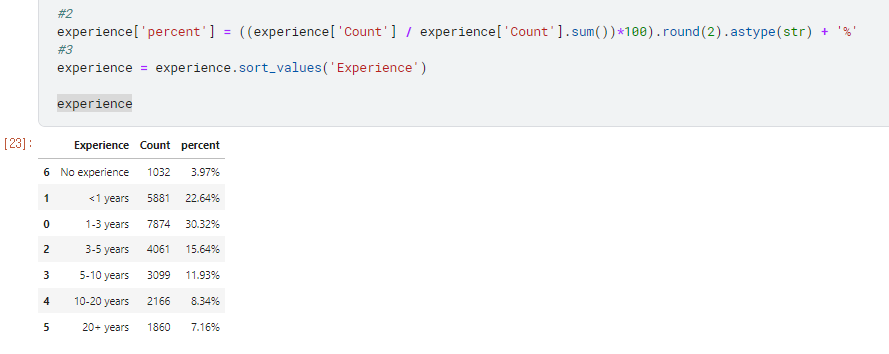
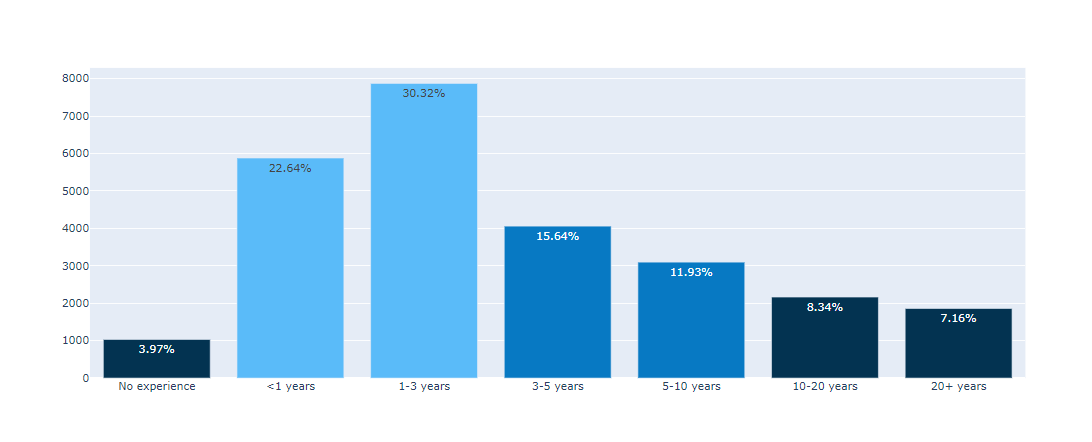
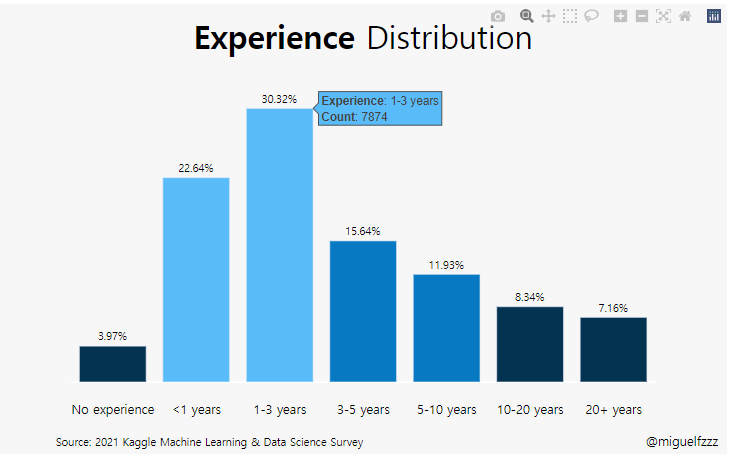
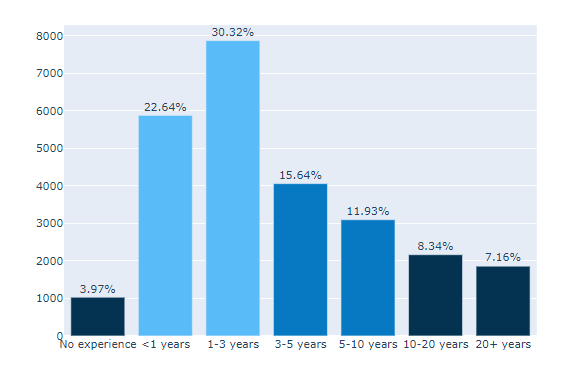
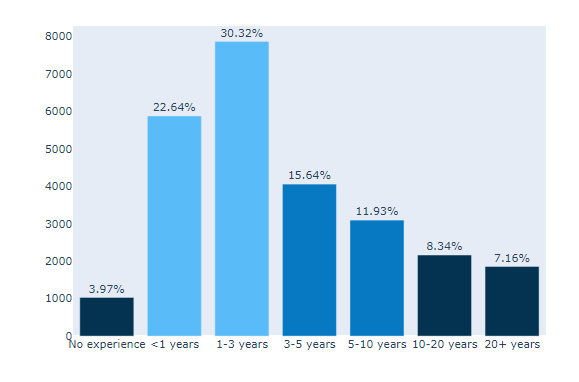
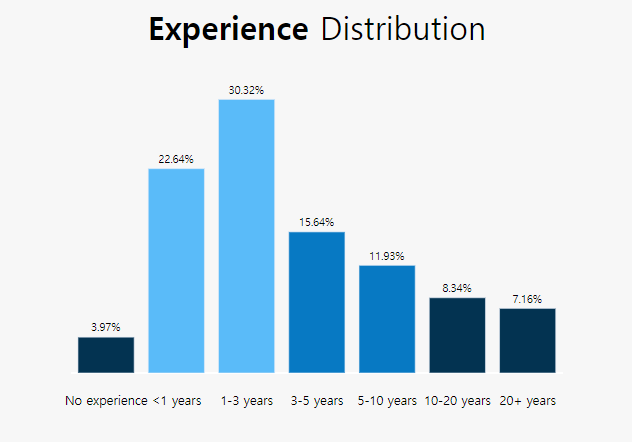
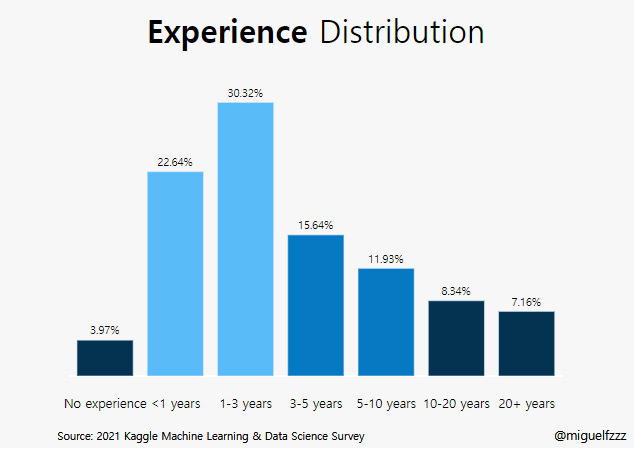
text=experience[‘percent’]
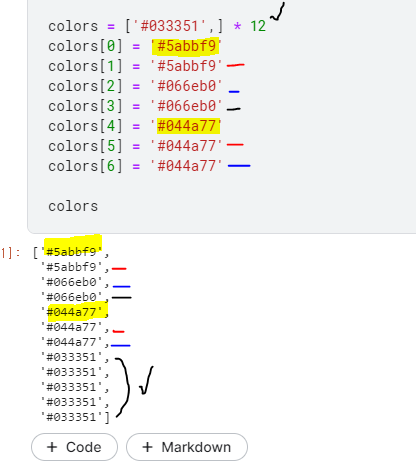
marker_color=colors
지정 해 준 colors를 사용.
(#6) : fig.update_traces()
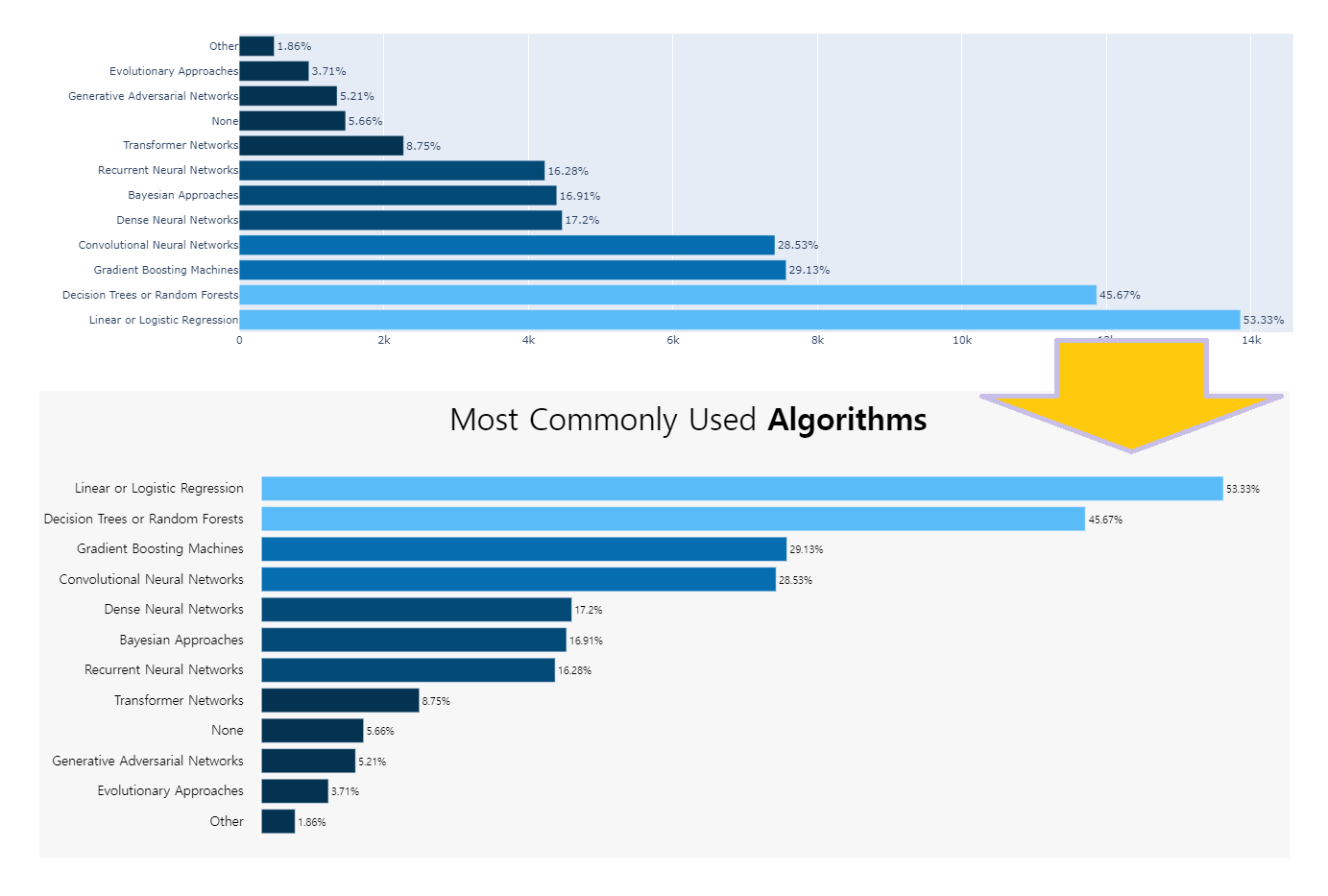
그래프 위에 캡션 다는 기능
Perform a property update operation on all traces that satisfy the specified selection criteria
지정된 선택 기준을 충족하는 모든 추적에 대해 속성 업데이트 작업 수행 (?? 전혀 모르겠군 !)
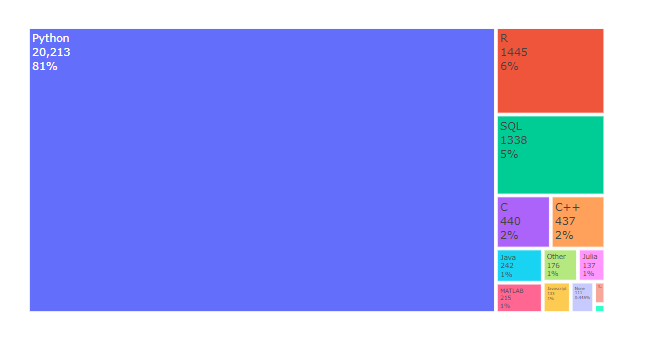
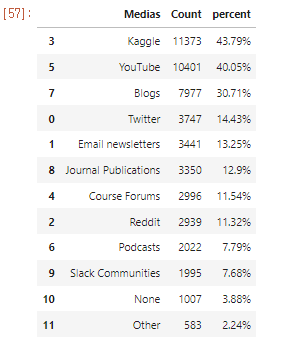
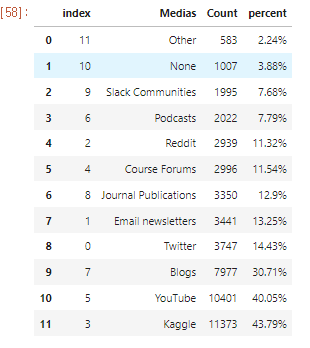
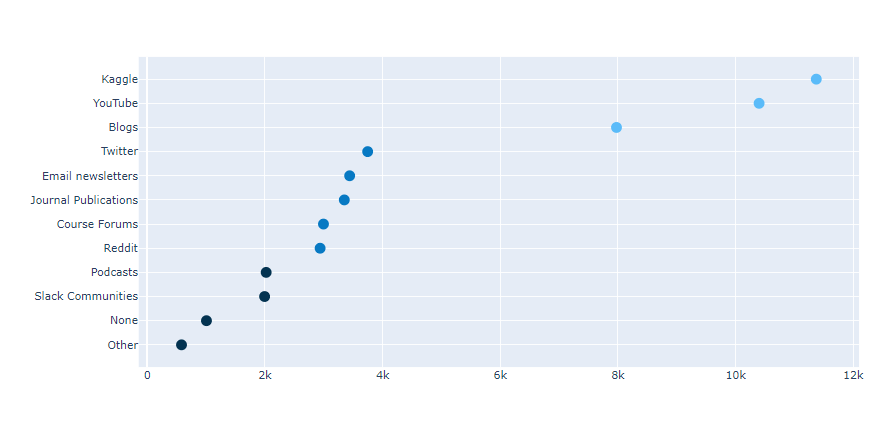
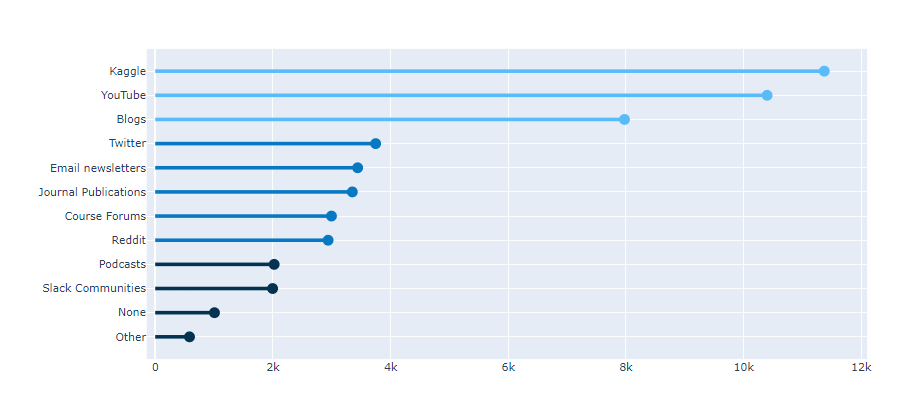
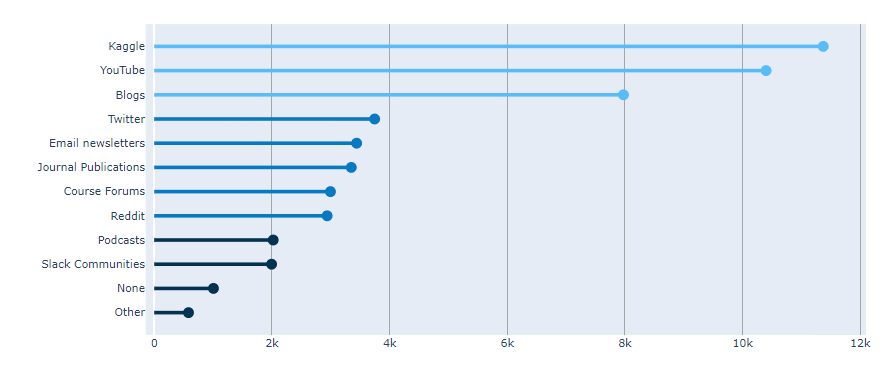
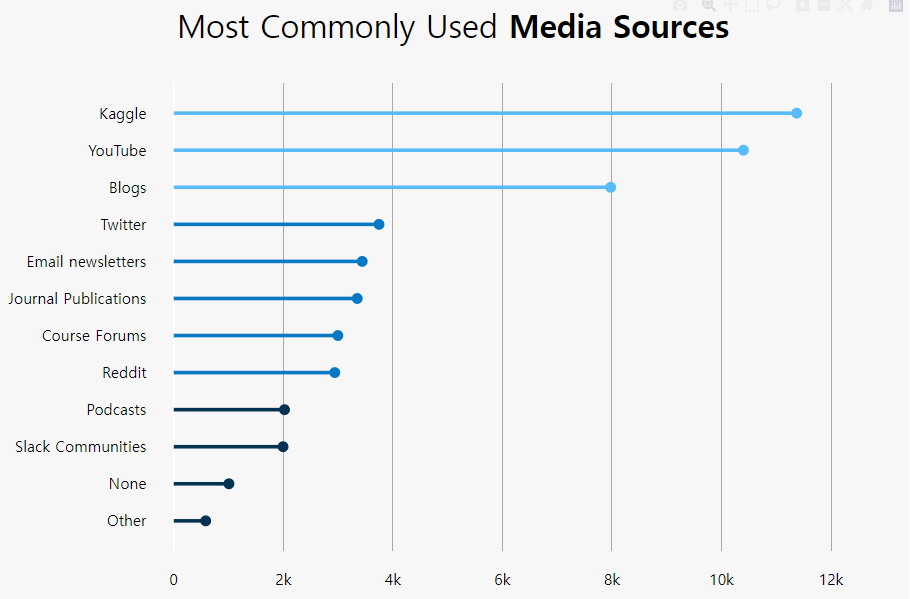
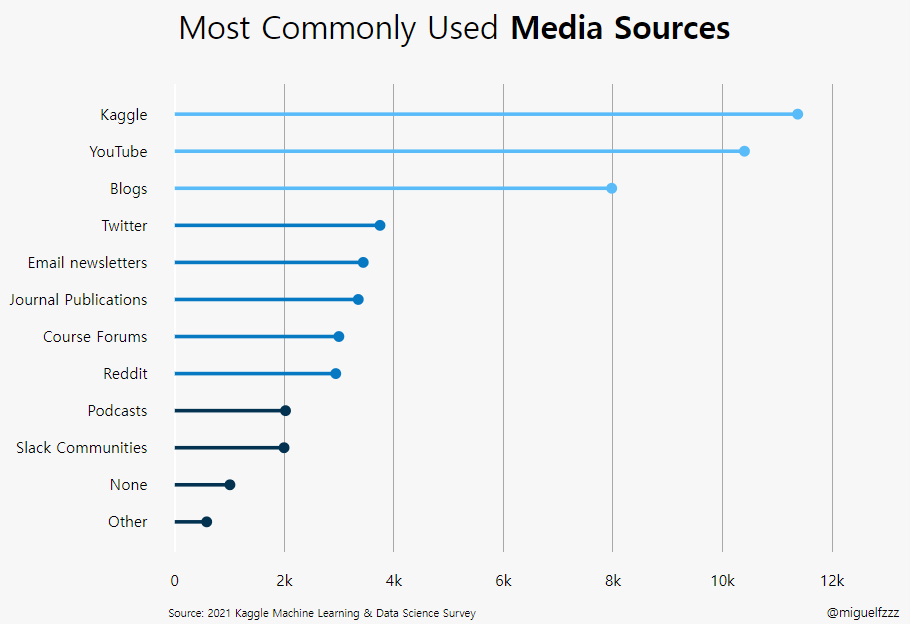
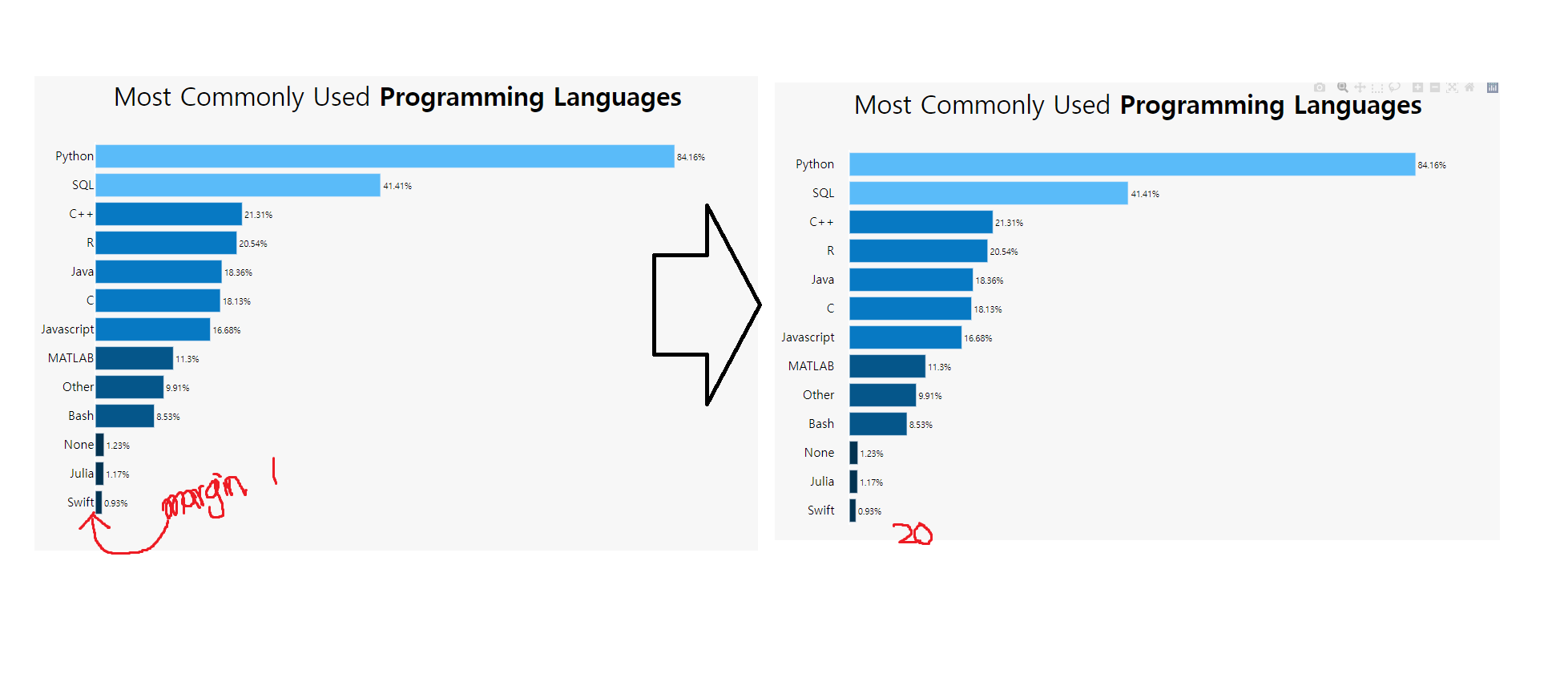
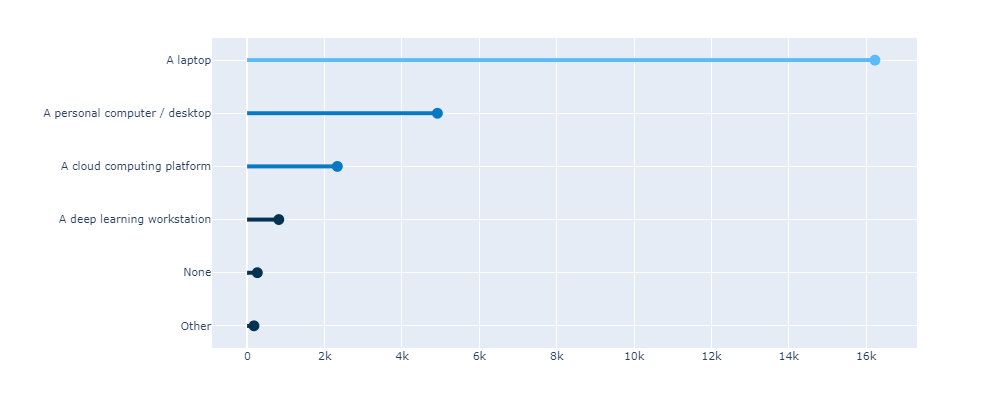
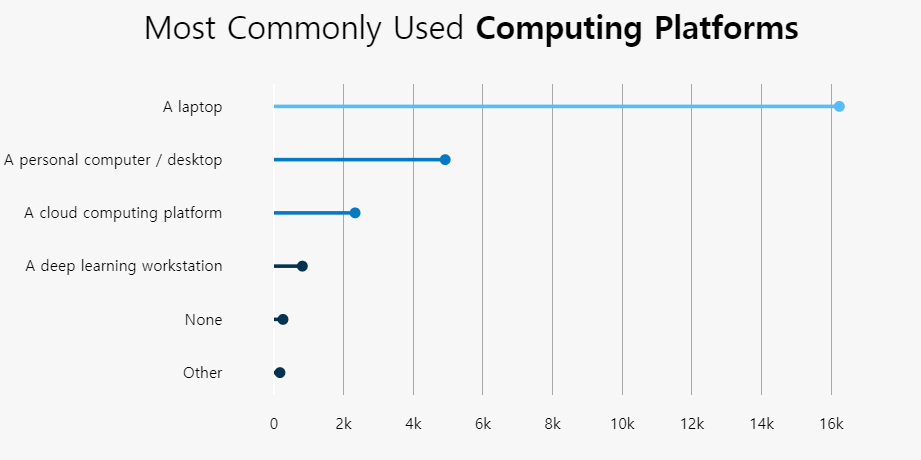
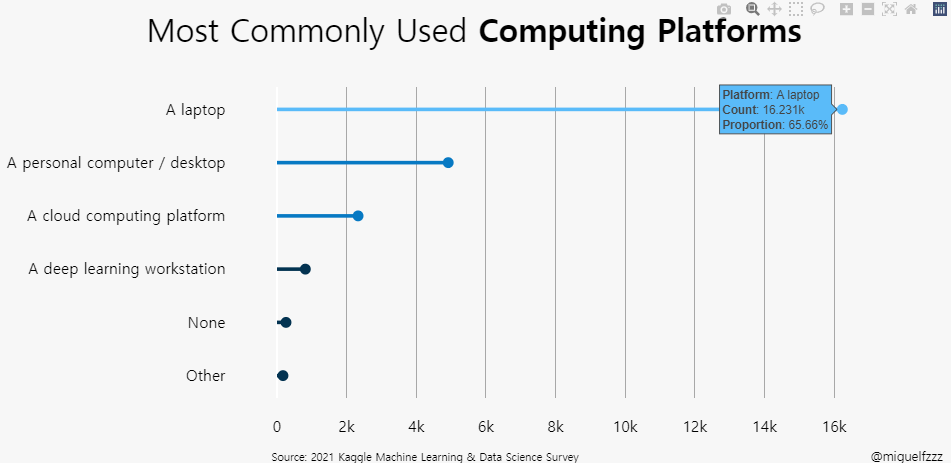
아래 본문과는 상관없는 data를 좀 보세요.
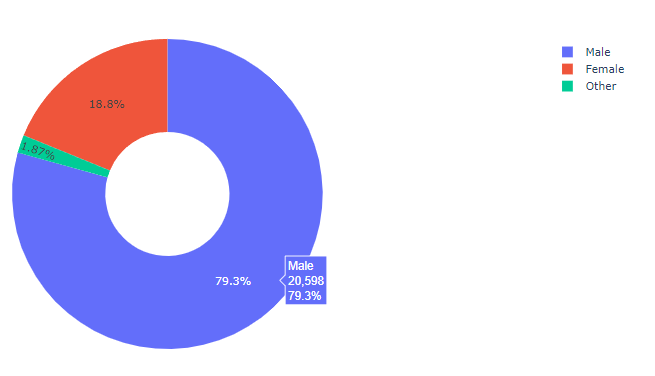
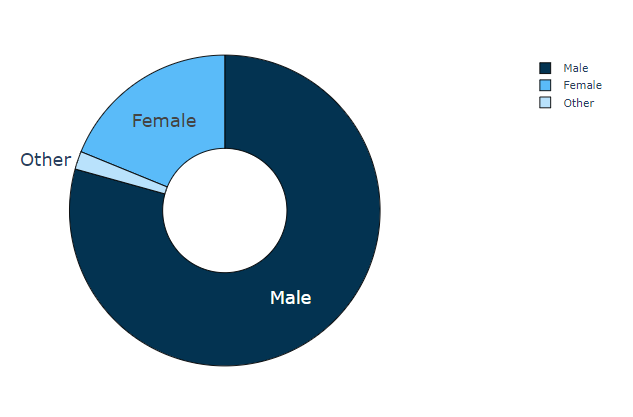
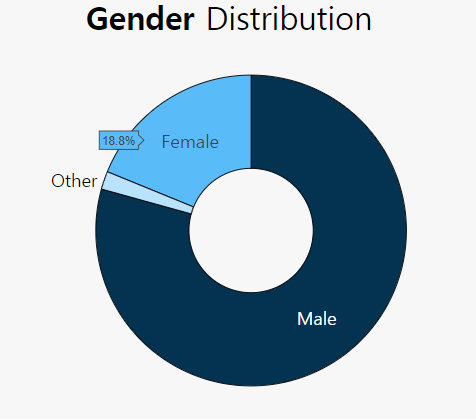
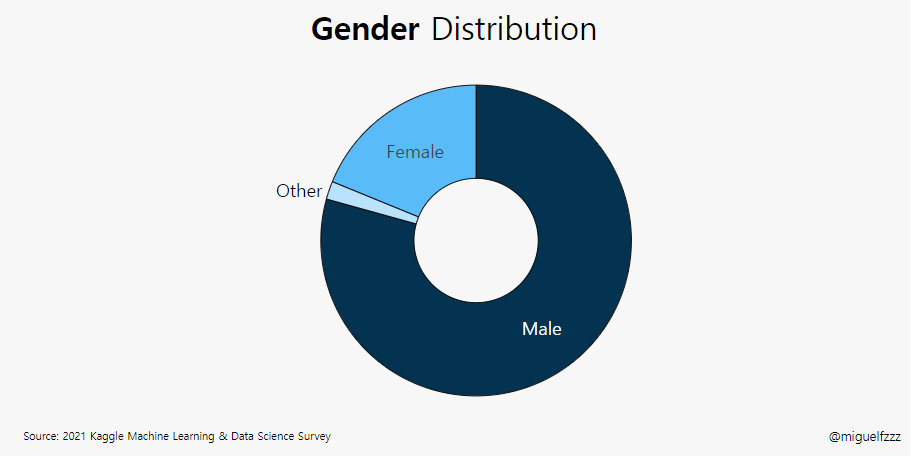
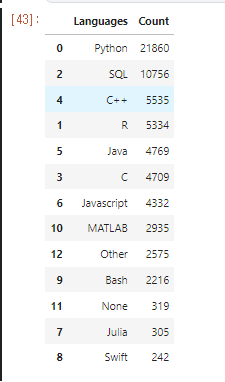
fig = go.Figure() # [str(x) + ' %' for x in np.round(val_pnt_df["%"].values, 1).tolist()] # Add Traces fig.add_bar(x = val_pnt_df.index, y = val_pnt_df['count'].values, text = [str(x) + ' %'for x in np.round(val_pnt_df["%"].values, 1).tolist()], textposition="auto")

.png)